6 Métodos numéricos y optimización con restricciones tipo caja
En este capítulo se presentan los fundamentos teóricos y computacionales de los métodos de optimización aplicados a problemas con restricciones tipo caja, es decir, aquellos en los que las variables de decisión se encuentran acotadas superior e inferiormente dentro de un dominio compacto. Este tipo de problemas es común en la modelación de sistemas físicos, económicos y logísticos, donde las condiciones naturales o estructurales limitan el espacio de búsqueda de soluciones. Siguiendo la metodología descrita por Bertsekas (2016), Capítulo 2; Luenberger y Ye (2016), Sección 8.4; Bazaraa, Sherali, y Shetty (2013), Sección 8.7 y Nocedal y Wright (2006), Sección 12.2, se adopta un enfoque basado en proyección, condiciones de optimalidad de Karush–Kuhn–Tucker y métodos de memoria limitada para resolver eficientemente estos problemas.
El desarrollo del capítulo se organiza en cinco secciones. En primer lugar, se introducen los fundamentos de los métodos iterativos de primer y segundo orden, enfatizando los mecanismos de actualización del gradiente y la aproximación del Hessiano. Posteriormente, se extiende el análisis hacia dominios con restricciones tipo caja, detallando la formulación y justificación estructural del algoritmo L-BFGS-B, uno de los más eficientes para resolver problemas de gran escala con cotas bajo el esquema de Byrd et al. (1995) y Nocedal y Wright (2006) capítulo 6. En la tercera sección se analizan los resultados teóricos de convergencia del método bajo hipótesis de regularidad, presentando un teorema global que garantiza la existencia de puntos estacionarios que satisfacen las condiciones de Karush-Kuhn-Tucker (KKT) Sección 4.7. En seguida, la cuarta parte describe la implementación computacional del algoritmo y los experimentos numéricos realizados para evaluar su desempeño frente a otros métodos clásicos de optimización sin restricciones. Finalmente, se incluye una discusión crítica acerca de las ventajas, limitaciones y posibles extensiones del enfoque propuesto.
El propósito de este capítulo es ofrecer una comprensión integral del método L-BFGS-B, integrando su base matemática, su estructura computacional y su relevancia práctica para la resolución eficiente de problemas con restricciones tipo caja.
6.1 Fundamentos de métodos iterativos de primer y segundo orden
6.1.1 Método de gradiente descendente y sus propiedades de convergencia
El método de gradiente descendente constituye el algoritmo más elemental dentro de los métodos iterativos de primer orden para la minimización no lineal de funciones diferenciables. Su fundamento se basa en la propiedad geométrica de que el gradiente de una función escalar \(f: \mathbb{R}^n \to \mathbb{R}\), diferenciable en un punto \(x \in \mathbb{R}^n\), apunta en la dirección de máximo crecimiento local. En consecuencia, la dirección opuesta, \(-\nabla f(x)\), indica un camino de descenso local siempre que \(\nabla f(x) \neq 0\) (véase Nocedal y Wright (2006), Capítulo 2, Sección 2.1, en particular la discusión sobre la dirección de máximo crecimiento, p. 14).
Formalmente, dado un punto inicial \(x_0 \in \mathbb{R}^n\), el método genera una sucesión \(\{x_k\}_{k \geq 0}\) definida por
\[ x_{k+1} = x_k - \alpha_k \nabla f(x_k), \]
donde \(\alpha_k > 0\) es la longitud de paso seleccionada en cada iteración mediante una búsqueda lineal adecuada.
La elección de \(\alpha_k\) resulta determinante para la convergencia. Una estrategia robusta impone las condiciones de Wolfe (Nocedal y Wright (2006), Sección 3.1, pp.33–34):
\[ f(x_k - \alpha_k \nabla f(x_k)) \le f(x_k) - c_1 \alpha_k \|\nabla f(x_k)\|^2, \] \[ \nabla f(x_k - \alpha_k \nabla f(x_k))^\top \nabla f(x_k) \ge c_2 \|\nabla f(x_k)\|^2, \]
donde \(0 < c_1 < c_2 < 1\). La primera asegura un descenso suficiente y la segunda evita pasos demasiado pequeños.
6.1.1.1 Propiedades de convergencia
Bajo las hipótesis:
- \(f\) es continuamente diferenciable (ver Sección 4.3) en un conjunto abierto que contiene al conjunto de nivel \(\mathcal{L} = \{x \in \mathbb{R}^n : f(x) \le f(x_0)\}\),
- \(\mathcal{L}\) es compacto (ver Sección 4.1),
el método de gradiente descendente con pasos que satisfacen las condiciones de Wolfe garantiza que
\[ \liminf_{k \to \infty} \|\nabla f(x_k)\| = 0. \]
Si, además, \(f\) es fuertemente convexa, es decir, existe \(m > 0\) tal que
\[ (\nabla f(x) - \nabla f(y))^\top (x - y) \ge m \|x - y\|^2, \]
entonces la sucesión \(\{x_k\}\) converge linealmente al minimizador \(x^\star\), cumpliendo
\[ \|x_{k+1} - x^\star\| \le \rho \|x_k - x^\star\|, \quad \rho \in (0,1). \]
6.1.1.2 Ejemplo ilustrativo
Consideremos \(f(x) = \tfrac{1}{2}x^\top A x - b^\top x\), con
\[ A = \begin{pmatrix} 2 & 0 \\ 0 & 10 \end{pmatrix}, \quad b = \begin{pmatrix} 0 \\ 0 \end{pmatrix}. \]
El gradiente es \(\nabla f(x) = A x\). Partiendo de \(x_0 = (1,1)^\top\), se obtiene mediante búsqueda lineal exacta:
\[ \alpha_0 = \frac{13}{126} \approx 0.1032, \quad x_1 = (0.7937, -0.0317)^\top. \]
La trayectoria oscila hacia \(x^\star = (0,0)^\top\), evidenciando la convergencia lineal y la influencia del número de condición \(\kappa(A) = 5\).
Este comportamiento justifica la necesidad de métodos que incorporen información de segundo orden, como los métodos de tipo cuasi-Newton, presentados en la siguiente sección.
6.1.2 Métodos cuasi-Newton: aproximación del Hessiano y convergencia superlineal
Antes de describir el esquema algorítmico, introducimos la noción de convergencia superlineal, que caracteriza la eficiencia asintótica de esta clase de métodos.
Sea \(\{x_k\}\) una sucesión generada por un algoritmo que converge a un punto óptimo \(x^\star\). Se dice que la convergencia es superlineal si
\[
\lim_{k \to \infty} \frac{\|x_{k+1} - x^\star\|}{\|x_k - x^\star\|} = 0.
\] Esta tasa es más rápida que la convergencia lineal y refleja una aceleración progresiva del algoritmo cerca de la solución. Los métodos cuasi-Newton, como BFGS, alcanzan esta tasa bajo hipótesis de regularidad (por ejemplo, \(f \in C^2\) con Hessiano Lipschitz-continuo) y búsquedas lineales que satisfagan las condiciones de Wolfe (Nocedal y Wright (2006), Sección 6.4).
Los métodos cuasi-Newton constituyen una clase fundamental de algoritmos iterativos para la minimización de funciones diferenciables sin restricciones, diseñados para emular el comportamiento del método de Newton sin requerir la evaluación explícita del Hessiano.
Los métodos cuasi-Newton constituyen una clase fundamental de algoritmos iterativos para la minimización de funciones diferenciables sin restricciones, diseñados para emular el comportamiento del método de Newton sin requerir la evaluación explícita del Hessiano \(\nabla^2 f(x_k)\). En lugar de ello, estos métodos construyen aproximaciones sucesivas \(B_k \in \mathbb{R}^{n \times n}\) (o \(H_k \approx (\nabla^2 f(x_k))^{-1}\)) a partir de la información de gradientes acumulada durante la iteración, logrando así tasas de convergencia superlineales bajo hipótesis razonables, como puede verse en la Sección 6.4 de Nocedal y Wright (2006).
Sea \(f : \mathbb{R}^n \to \mathbb{R}\) una función continuamente diferenciable. El esquema genérico de un método cuasi-Newton se expresa como
\[ x_{k+1} = x_k - \alpha_k B_k^{-1} \nabla f(x_k), \]
donde \(B_k\) es una matriz simétrica definida positiva que aproxima el Hessiano \(\nabla^2 f(x_k)\), y \(\alpha_k > 0\) se elige mediante una búsqueda lineal (por ejemplo, las condiciones de Wolfe).
La actualización de \(B_k\) se basa en la ecuación secante, derivada de la expansión de Taylor de primer orden del gradiente:
\[ \nabla f(x_{k+1}) - \nabla f(x_k) \approx \nabla^2 f(x_k)(x_{k+1} - x_k). \]
Definiendo los incrementos
\[ s_k := x_{k+1} - x_k, \quad y_k := \nabla f(x_{k+1}) - \nabla f(x_k), \]
la ecuación secante exige que la nueva aproximación \(B_{k+1}\) satisfaga
\[ B_{k+1} s_k = y_k. \]
Dado que esta ecuación impone solo \(n\) restricciones lineales sobre las \(\tfrac{n(n+1)}{2}\) entradas independientes de una matriz simétrica, se requiere un criterio adicional para determinar \(B_{k+1}\) de forma única. Los métodos cuasi-Newton clásicos surgen al imponer que \(B_{k+1}\) sea la matriz más cercana a \(B_k\) en alguna norma matricial adecuada, sujeta a la ecuación secante y a la simetría.
6.1.2.1 El método BFGS
El algoritmo BFGS (Broyden–Fletcher–Goldfarb–Shanno) es el método cuasi-Newton más utilizado en la práctica. Se obtiene al minimizar la distancia entre \(H_{k+1} = B_{k+1}^{-1}\) y \(H_k = B_k^{-1}\) en una norma de Frobenius ponderada que garantiza invariancia de escala. Recordemos que, dada una matriz \(A \in \mathbb{R}^{n \times n}\) y una matriz de peso simétrica definida positiva \(W\), la norma de Frobenius ponderada se define como \[ \|A\|_W = \|W^{1/2} A W^{1/2}\|_F = \sqrt{\operatorname{tr}\!\big(W A^\top W A\big)}, \] donde \(\|\cdot\|_F\) es la norma de Frobenius estándar. En el contexto del método BFGS, se elige \(W = B_k\) (o equivalentemente se trabaja en la métrica inducida por \(H_k\)) para asegurar que la actualización sea invariante ante cambios de escala de las variables. La fórmula de actualización de la matriz inversa resultante es
\[ H_{k+1} = (I - \rho_k s_k y_k^\top) H_k (I - \rho_k y_k s_k^\top) + \rho_k s_k s_k^\top, \]
donde \[\rho_k = (y_k^\top s_k)^{-1}\] y se asume \[y_k^\top s_k > 0\] (condición de curvatura), garantizada si la búsqueda lineal cumple las condiciones de Wolfe.
El método BFGS posee propiedades teóricas destacadas:
Si \(f\) es dos veces continuamente diferenciable y su Hessiano \(\nabla^2 f\) es Lipschitz-continuo (ver Sección 4.3) en una vecindad de un minimizador \(x^\star\), y la búsqueda lineal satisface las condiciones de Wolfe, entonces la sucesión \(\{x_k\}\) cumple
\[ \lim_{k \to \infty} \|x_k - x^\star\| = 0, \]
y la convergencia es superlineal:
\[ \lim_{k \to \infty} \frac{\|x_{k+1} - x^\star\|}{\|x_k - x^\star\|} = 0. \]
Este resultado se basa en la caracterización contenida en la investigacion de Dennis y Moré (1977):
\[ \lim_{k \to \infty} \frac{\|(B_k - \nabla^2 f(x^\star)) s_k\|}{\|s_k\|} = 0. \]
Si además \(f\) es cuadrática y fuertemente convexa, BFGS converge en a lo sumo \(n\) pasos, generando direcciones conjugadas (ver Sección 4.3) respecto al Hessiano exacto. Nos referimos a que, si \[ f(x) = \tfrac{1}{2} x^\top Q x - b^\top x + c, \] con \(Q = \nabla^2 f\) simétrica definida positiva, entonces las direcciones de búsqueda \(\{p_0, p_1, \dots, p_{n-1}\}\) producidas por el método satisfacen la condición de conjugación \[ p_i^\top Q\, p_j = 0 \quad \text{para todo } i \neq j, \] es decir, son mutuamente ortogonales en la métrica inducida por \(Q\). Esta propiedad es característica de los métodos tipo conjugado (como el método del gradiente conjugado) y garantiza que, en ausencia de errores de redondeo, se alcance el mínimo exacto en a lo mas \(n\) iteraciones.
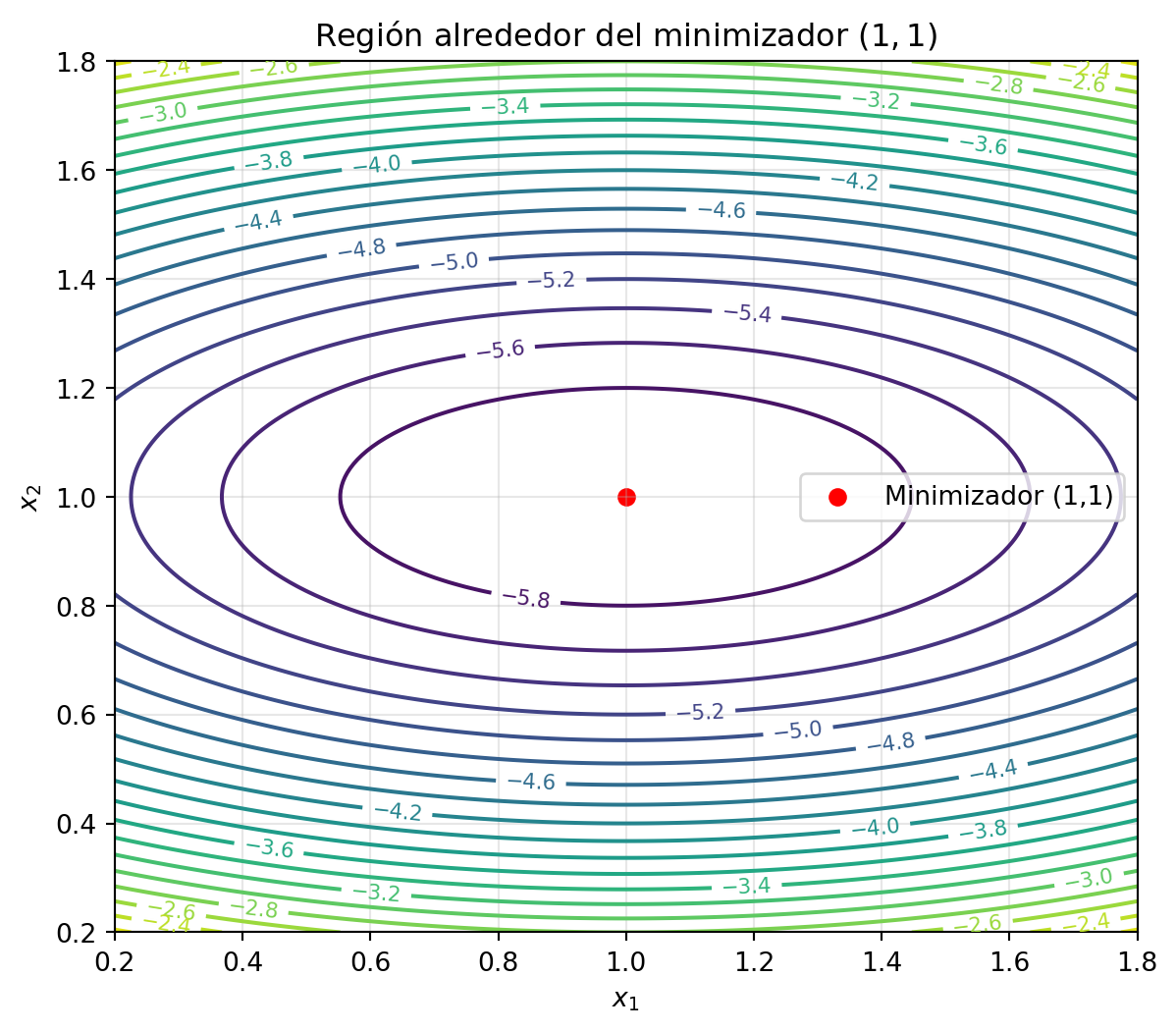
6.1.2.2 Ejemplo ilustrativo: minimización cuadrática con BFGS
Sea la función cuadrática fuertemente convexa en \(\mathbb{R}^2\):
\[ f(x) = \tfrac{1}{2}x^\top A x - b^\top x, \quad A = \begin{pmatrix} 2 & 0 \\ 0 & 10 \end{pmatrix}, \quad b = \begin{pmatrix} 2 \\ 10 \end{pmatrix}, \]
cuyo minimizador es \(x^\star = A^{-1}b = (1, 1)^\top\).
Partimos de \(x_0 = (0, 0)^\top\) y elegimos \(H_0 = I\) como aproximación inicial de la inversa del Hessiano. Utilizamos búsqueda lineal exacta.
Iteración \(k = 0\):
- \(\nabla f(x_0) = A x_0 - b = (-2, -10)^\top\).
- Dirección: \(p_0 = -H_0 \nabla f(x_0) = (2, 10)^\top\).
- Paso óptimo: \[ \alpha_0 = \frac{\nabla f(x_0)^\top p_0}{p_0^\top A p_0} = \frac{104}{1008} = \frac{13}{126} \approx 0.1032. \]
- Nuevo punto: \[ x_1 = x_0 + \alpha_0 p_0 = (0.2063, 1.0317)^\top. \]
- Incrementos: \[ s_0 = x_1 - x_0, \quad y_0 = \nabla f(x_1) - \nabla f(x_0) = A s_0. \]
- Condición de curvatura: \(y_0^\top s_0 \approx 10.746 > 0\).
- Actualización BFGS: \[ H_1 \approx \begin{pmatrix} 0.503 & -0.004 \\ -0.004 & 0.100 \end{pmatrix}, \] que aproxima bien a \(A^{-1} = \operatorname{diag}(0.5, 0.1)\).
Iteración \(k = 1\):
- \(\nabla f(x_1) = A x_1 - b \approx (-1.587, 0.317)^\top\).
- Dirección: \(p_1 = -H_1 \nabla f(x_1) \approx (0.792, -0.032)^\top\).
- Paso óptimo: \(\alpha_1 \approx 1.033\).
- Nuevo punto: \(x_2 \approx (1.022, 0.999)^\top\), muy cercano a \(x^\star = (1,1)^\top\).
En solo dos iteraciones el algoritmo reduce el error residual en más de un orden de magnitud, demostrando la convergencia superlineal (ver Sección 6.1.2) del método BFGS para funciones cuadráticas. Este comportamiento se mantiene en problemas no cuadráticos siempre que el condicionamiento sea razonable y la búsqueda lineal sea suficientemente precisa.
6.1.3 Familia Broyden y el método BFGS como caso prototípico
La clase de métodos cuasi-Newton puede organizarse en torno a la familia de actualizaciones de Broyden, un conjunto paramétrico de fórmulas que preservan la ecuación secante y generan matrices simétricas actualizadas a partir de la información de gradiente acumulada. Esta familia engloba los métodos más relevantes en la práctica, entre ellos el BFGS (Broyden–Fletcher–Goldfarb–Shanno) y el DFP (Davidon–Fletcher–Powell), y permite, como se expone en la Sección 6.3 de Nocedal y Wright (2006), analizar de forma unificada sus propiedades de convergencia, estabilidad y eficiencia computacional.
Sea \(f : \mathbb{R}^n \to \mathbb{R}\) una función dos veces continuamente diferenciable (ver Sección 4.3). En cada iteración \(k\), se dispone de los incrementos
\[ s_k := x_{k+1} - x_k, \quad y_k := \nabla f(x_{k+1}) - \nabla f(x_k), \]
y se busca una matriz simétrica \(B_{k+1} \in \mathbb{R}^{n \times n}\) que satisfaga la ecuación secante
\[ B_{k+1} s_k = y_k. \tag{6.1}\]
La familia de Broyden se define como el conjunto de actualizaciones
\[ B_{k+1}(\phi_k) = B_k - \frac{B_k s_k s_k^\top B_k}{s_k^\top B_k s_k} + \frac{y_k y_k^\top}{y_k^\top s_k} + \phi_k\, v_k v_k^\top, \tag{6.2}\]
donde
\[ v_k = \left(\frac{y_k}{y_k^\top s_k} - \frac{B_k s_k}{s_k^\top B_k s_k}\right), \tag{6.3}\]
y \(\phi_k \in \mathbb{R}\) es un parámetro que determina el miembro particular de la familia.
La fórmula Ecuación 6.2 puede interpretarse como una combinación convexa de dos actualizaciones extremas:
- BFGS: \(\phi_k = 0\),
- DFP: \(\phi_k = 1\).
De hecho,
\[ B_{k+1}(\phi_k) = (1 - \phi_k) B_{k+1}^{\text{BFGS}} + \phi_k B_{k+1}^{\text{DFP}}. \tag{6.4}\]
6.1.3.1 Propiedades de la familia restringida de Broyden
Una subclase especialmente relevante es la familia restringida de Broyden, asociada a \(\phi_k \in [0,1]\). Bajo la condición de curvatura
\[ y_k^\top s_k > 0, \tag{6.5}\]
garantizada si la búsqueda lineal cumple las condiciones de Wolfe, todos los miembros de esta subclase preservan la definida positividad de \(B_k\), siempre que \(B_0\) sea simétrica definida positiva. Esta propiedad asegura que la dirección de búsqueda
\[ p_k = -B_k^{-1} \nabla f(x_k) \tag{6.6}\]
sea de descenso. Además, si \(f\) es una función cuadrática fuertemente convexa (ver Sección 4.3), cualquier método de la familia restringida de Broyden converge en a lo sumo \(n\) pasos, generando direcciones conjugadas (ver Sección 4.3) respecto al Hessiano exacto \(\nabla^2 f\) Dennis y Moré (1977), Sección 5.
6.1.3.2 El método BFGS como caso prototípico
El método BFGS corresponde a \(\phi_k = 0\) en Ecuación 6.2. Su fórmula de actualización de la inversa del Hessiano aproximado \(H_k = B_k^{-1}\) es
\[ H_{k+1} = (I - \rho_k s_k y_k^\top) H_k (I - \rho_k y_k s_k^\top) + \rho_k s_k s_k^\top, \quad \rho_k = (y_k^\top s_k)^{-1}. \tag{6.7}\]
Esta formulación evita la inversión explícita de matrices y facilita el cálculo de la dirección de búsqueda:
\[ p_k = -H_k \nabla f(x_k). \]
El método BFGS se distingue por:
- Su invariancia afín: el comportamiento es independiente de escalas y transformaciones lineales.
- Su propiedad de autocorrección (self-scaling): si \(H_k\) es una mala aproximación, la iteración corrige rápidamente la orientación de la matriz.
- Su convergencia superlineal está garantizada bajo hipótesis estándar de suavidad, es decir, que \(f\) sea dos veces continuamente diferenciable (ver Sección 4.3) y que su gradiente (o, equivalentemente, su Hessiano) sea Lipschitz continuo en una vecindad del minimizador, junto con el uso de una búsqueda lineal que satisfaga las condiciones de Wolfe, como se establece en Fletcher (1987), Sección 3.4.
6.1.3.3 Ejemplo ilustrativo: actualización BFGS en \(\mathbb{R}^2\)
Sea
\[ f(x) = \tfrac{1}{2} x^\top A x - b^\top x, \quad A = \begin{pmatrix} 4 & 1 \\ 1 & 2 \end{pmatrix}, \quad b = \begin{pmatrix} 1 \\ 1 \end{pmatrix}. \]
El minimizador es \(x^\star = A^{-1}b = (1/7, 3/7)^\top \approx (0.1429, 0.4286)^\top\). Partimos de \(x_0 = (0,0)^\top\) y \(H_0 = I\).
Iteración \(k = 0\):
- \(\nabla f(x_0) = (-1, -1)^\top\).
- \(p_0 = (1,1)^\top\).
- \(\alpha_0 = \frac{2}{8} = 0.25\).
- \(x_1 = (0.25, 0.25)^\top\).
- \(\nabla f(x_1) = (0.25, -0.25)^\top\).
- \(s_0 = (0.25, 0.25)^\top\), \(y_0 = (1.25, 0.75)^\top\).
- \(y_0^\top s_0 = 0.5 > 0\), \(\rho_0 = 2\).
- \(H_1 \approx \begin{pmatrix} 0.406 & -0.344 \\ -0.344 & 0.906 \end{pmatrix}\).
Iteración \(k = 1\):
- \(p_1 = -H_1 (0.25, -0.25)^\top \approx (-0.1875, 0.3125)^\top\).
- \(\alpha_1 \approx 0.857\), \(x_2 \approx (0.089, 0.518)^\top\).
Tras dos iteraciones, \(\|x_2 - x^\star\| \approx 0.09\), y \(H_1\) aproxima bien \(A^{-1}\), demostrando la capacidad del método para capturar la geometría de segundo orden con pocas actualizaciones.
El método BFGS representa el caso prototípico dentro de la familia de Broyden, al combinar eficiencia computacional, robustez teórica y convergencia superlineal incluso en problemas moderadamente mal condicionados.
6.2 Extensión a dominios con restricciones tipo caja
En la práctica, muchos problemas de optimización imponen límites naturales o estructurales sobre las variables de decisión, dando origen a los denominados problemas con restricciones tipo caja. En este contexto, las variables están acotadas por límites inferiores y superiores que definen un dominio factible de la forma \(\Omega = \{x \in \mathbb{R}^n : \ell_i \le x_i \le u_i\}\).
Estos problemas aparecen con frecuencia en aplicaciones de ingeniería, finanzas y logística, donde ciertas magnitudes no pueden sobrepasar intervalos físicamente admisibles. Extender los métodos de optimización a dominios de este tipo requiere incorporar operadores de proyección ortogonal que aseguren la factibilidad de cada iteración sin comprometer la convergencia del algoritmo. La presente sección desarrolla las propiedades analíticas de dicha proyección, que constituye el núcleo geométrico de los métodos con restricciones tipo caja.
6.2.1 Proyección ortogonal sobre conjuntos de cotas: definición y propiedades
En la optimización con restricciones tipo caja, el conjunto factible se define como
\[ \Omega = \{x \in \mathbb{R}^n : \ell_i \le x_i \le u_i,\; i = 1,\dots,n\}, \]
donde \(\ell = (\ell_1,\dots,\ell_n)^\top \in \mathbb{R}^n \cup \{-\infty\}^n\) y \(u = (u_1,\dots,u_n)^\top \in \mathbb{R}^n \cup \{+\infty\}^n\) satisfacen \(\ell_i < u_i\) para todo \(i\). Este conjunto es convexo, cerrado y no vacío, lo que garantiza que la proyección ortogonal de cualquier punto \(z \in \mathbb{R}^n\) sobre \(\Omega\) está bien definida y es única.
6.2.1.1 Proyección Ortogonal
La proyección ortogonal de \(z\) sobre \(\Omega\), denotada \(P_\Omega(z)\), se define como la solución única del problema de minimización
\[ P_\Omega(z) = \arg\min_{x \in \Omega} \tfrac{1}{2}\|x - z\|^2. \tag{6.8}\]
Dado que \(\Omega\) es un producto cartesiano de intervalos cerrados, la proyección se descompone coordenada a coordenada:
\[ [P_\Omega(z)]_i = \min\{u_i,\, \max\{\ell_i,\, z_i\}\}, \quad i = 1,\dots,n. \tag{6.9}\]
Esta expresión corresponde a la llamada función de recorte (clipping function), que restringe cada componente de \(z\) al intervalo factible \([\ell_i,u_i]\).
6.2.1.2 Propiedades fundamentales
No expansividad
\[ \|P_\Omega(z) - P_\Omega(w)\| \le \|z - w\|, \quad \forall z,w \in \mathbb{R}^n. \tag{6.10}\]
Por tanto, \(P_\Omega\) es una aplicación Lipschitz continua (ver Sección 4.3) con constante 1, lo que implica estabilidad numérica.
Caracterización variacional
Un punto \(x^\star \in \Omega\) satisface \(x^\star = P_\Omega(z)\), si y solo si,
\[ (z - x^\star)^\top (x - x^\star) \le 0, \quad \forall x \in \Omega. \tag{6.11}\]
Geométricamente, esto significa que el vector residual \(z - x^\star\) forma un ángulo obtuso con cualquier dirección factible desde \(x^\star\).
Condiciones de complementariedad (KKT)
Para cada \(i\) se cumple
\[ \begin{cases} x_i = \ell_i &\Rightarrow z_i \le \ell_i,\\[4pt] x_i = u_i &\Rightarrow z_i \ge u_i,\\[4pt] \ell_i < x_i < u_i &\Rightarrow z_i = x_i, \end{cases} \tag{6.12}\]
que equivalen a las condiciones de optimalidad de primer orden del problema cuadrático (Ecuación 6.8).
6.2.1.3 Ejemplo: proyección en \(\mathbb{R}^3\)
Sea
\[ \Omega = \{x \in \mathbb{R}^3 : 1 \le x_1 \le 3,\; x_2 \le 2,\; x_3 \ge 0\}, \quad z = (0.5,\, 2.5,\, -1.2)^\top. \]
Aplicando Ecuación 6.9 coordenada a coordenada:
- \(x_1^\star = \min\{3, \max\{1, 0.5\}\} = 1\),
- \(x_2^\star = \min\{2, \max\{-\infty, 2.5\}\} = 2\),
- \(x_3^\star = \min\{+\infty, \max\{0, -1.2\}\} = 0\).
Por tanto,
\[ P_\Omega(z) = (1,\, 2,\, 0)^\top. \]
Comprobamos la caracterización variacional:
\[ (z - x^\star)^\top (x - x^\star) = (-0.5,\, 0.5,\, -1.2)^\top \cdot (x_1-1,\, x_2-2,\, x_3-0). \]
Dado que \(x_1 \ge 1\), \(x_2 \le 2\), \(x_3 \ge 0\), cada término parcial es no positivo, y la suma total \(\le 0\).
Asimismo, las condiciones Ecuación 6.12 se satisfacen coordenada a coordenada: \(x_1^\star=1\) con \(z_1=0.5\le1\), \(x_2^\star=2\) con \(z_2=2.5\ge2\), y \(x_3^\star=0\) con \(z_3=-1.2\le0\).
Este ejemplo ilustra cómo la proyección actúa localmente sobre cada componente, garantizando factibilidad sin resolver sistemas lineales. Su simplicidad y propiedades de estabilidad hacen que el operador \(P_\Omega\) sea esencial en algoritmos de optimización a gran escala, como el método L-BFGS-B, en el cual se aplica en cada iteración para mantener las variables dentro de los límites definidos.
6.2.2 El algoritmo L-BFGS-B: formulación y justificación estructural
El algoritmo L-BFGS-B (Limited-memory BFGS with Bounds) extiende el método cuasi-Newton BFGS al caso de restricciones tipo caja, es decir, dominios de la forma
\[ \Omega = \{x \in \mathbb{R}^n : \ell \le x \le u\}, \]
donde las desigualdades son componente a componente y \(\ell, u \in \mathbb{R}^n \cup \{\pm\infty\}^n\) con \(\ell_i < u_i\).
El método integra tres ideas fundamentales:
- Aproximación cuasi-Newton de memoria limitada, evitando el almacenamiento completo de matrices densas;
- Proyección ortogonal sobre \(\Omega\) para mantener factibilidad;
- Retención parcial de información de curvatura, conservando sólo las \(m\) parejas más recientes \((s_i, y_i)\).
6.2.2.1 Formulación del algoritmo
Dado un punto inicial \(x_0 \in \Omega\), el esquema iterativo se expresa como
\[ x_{k+1} = P_\Omega\big(x_k - \alpha_k H_k \nabla f(x_k)\big), \tag{6.13}\]
donde \(\alpha_k > 0\) satisface las condiciones de Wolfe y \(H_k\) es la aproximación de memoria limitada al inverso del Hessiano, construida mediante las \(m\) actualizaciones más recientes:
\[ s_i = x_{i+1} - x_i, \qquad y_i = \nabla f(x_{i+1}) - \nabla f(x_i), \quad i = k-m,\dots,k-1, \]
con \(y_i^\top s_i > 0\) (condición de curvatura).
La proyección \(P_\Omega\) se calcula coordenada a coordenada como
\[ [P_\Omega(z)]_i = \min\{u_i, \max\{\ell_i, z_i\}\}, \quad i=1,\dots,n. \tag{6.14}\]
El producto \(H_k \nabla f(x_k)\) se obtiene por la recursión de dos bucles, iniciada con \(H_k^{(0)} = \gamma_k I\), donde
\[ \gamma_k = \frac{s_{k-1}^\top y_{k-1}}{y_{k-1}^\top y_{k-1}}. \tag{6.15}\]
Este escalamiento mejora la estabilidad numérica y la aceptación de pasos unitarios.
6.2.2.2 Justificación estructural
El esquema Ecuación 6.13 garantiza factibilidad a cada iteración mediante la proyección \(P_\Omega\).
Definiendo el conjunto de índices activos
\[ \mathcal{A}_k = \{i : x_{k,i} = \ell_i \text{ o } x_{k,i} = u_i\}, \]
el método se comporta localmente como BFGS en los índices inactivos (\(i \notin \mathcal{A}_k\)) y mantiene las componentes activas en las cotas.
De este modo, la actualización proyectada puede interpretarse como
\[ x_{k+1} = \operatorname{Proj}_\Omega\big(x_k - \alpha_k \nabla^2 f(x_k)^{-1} \nabla f(x_k)\big), \]
con \(\nabla^2 f(x_k)^{-1}\) sustituido por la aproximación limitada \(H_k\).
Esta interpretación explica por qué L-BFGS-B conserva tanto la factibilidad como las propiedades de descenso y la convergencia superlineal del BFGS original.
En términos computacionales, el método BFGS requiere \(\mathcal{O}(n^2)\) unidades de memoria. Esto se debe a que, en cada iteración, el algoritmo mantiene una representación explícita de una matriz simétrica \(H_k \in \mathbb{R}^{n \times n}\) que aproxima la inversa del Hessiano de la función objetivo. El almacenamiento de dicha matriz implica retener el orden de \(n^2\) números reales en memoria principal, lo cual constituye un costo cuadrático en la dimensión del problema. Este requisito es inherente a la formulación clásica del método, ya que tanto la actualización de \(H_k\) mediante la fórmula cuasi-Newton como el cálculo de la dirección de búsqueda \(p_k = -H_k \nabla f(x_k)\) dependen de acceso directo a todos los elementos de la matriz. En problemas de gran escala, donde \(n\) puede alcanzar órdenes de magnitud de \(10^5\) o más, este costo se vuelve prohibitivo desde el punto de vista práctico. En contraste, el algoritmo L-BFGS-B evita el almacenamiento explícito de \(H_k\) y solo retiene los últimos \(m\) pares de vectores \((s_k, y_k)\), lo que reduce el requerimiento de memoria a \(\mathcal{O}(mn)\), con \(m \ll n\) (típicamente \(3 \leq m \leq 20\)).
6.2.2.3 Ejemplo: minimización cuadrática con restricciones tipo caja
Considérese
\[ \min_{x \in \mathbb{R}^2} f(x) = (x_1 - 2)^2 + (x_2 - 1)^2 \quad \text{sujeto a} \quad 1 \le x_1 \le 3, \; x_2 \ge 0. \]
El minimizador irrestricto \(x^\star = (2,1)^\top\) pertenece a \(\Omega\), por lo que coincide con el minimizador restringido.
Con \(m=1\) y \(x_0=(1,0)^\top\), el procedimiento es:
Iteración 0
\(\nabla f(x_0)=(-2,-2)^\top\), \(H_0=I\), \(d_0=(2,2)^\top\).
Con \(\alpha_0=1\), se obtiene \(\tilde{x}_1=(3,2)^\top\) y \(x_1=P_\Omega(\tilde{x}_1)=(3,2)^\top\).
\(\nabla f(x_1)=(2,2)^\top\), \(s_0=(2,2)^\top\), \(y_0=(4,4)^\top\).
Iteración 1
\(\gamma_1=\tfrac{s_0^\top y_0}{y_0^\top y_0}=0.5\),
\(H_1^{(0)}=0.5I\).
Aplicando la recursión de dos bucles:
\(q=\nabla f(x_1)\), \(\alpha_0=0.5\), \(q=q-0.5y_0=(0,0)^\top\),
\(r=H_1^{(0)}q=(0,0)^\top\),
\(r=r+s_0(\alpha_0-\tfrac{y_0^\top r}{y_0^\top s_0})=(1,1)^\top\).
Dirección \(d_1=-r=(-1,-1)^\top\).
Con \(\alpha_1=1\), \(\tilde{x}_2=(2,1)^\top\), \(x_2=P_\Omega(\tilde{x}_2)=(2,1)^\top\).
El método converge en dos iteraciones, demostrando que la estructura de memoria limitada y la proyección garantizan simultáneamente eficiencia y factibilidad.
La formulación L-BFGS-B preserva las propiedades de convergencia global del BFGS bajo las hipótesis de suavidad y curvatura positiva. Para más detalles Byrd et al. (1995); Zhu et al. (1997), y constituye uno de los métodos estándar para problemas de gran escala con restricciones tipo caja.
6.2.3 Condiciones de optimalidad bajo cotas: KKT para problemas con restricciones tipo caja
Tras haber introducido la formulación proyectada del algoritmo L-BFGS-B, resulta necesario caracterizar formalmente las condiciones de optimalidad que dicho método busca satisfacer. En particular, cuando el dominio está delimitado por cotas inferiores y superiores, las condiciones de Karush–Kuhn–Tucker (KKT) Sección 4.7 adquieren una estructura particularmente simple y separable por coordenadas. Esta sección desarrolla esa caracterización, que constituye el fundamento teórico de la convergencia de los métodos con restricciones tipo caja.
Consideremos el problema de optimización
\[ \min_{x \in \mathbb{R}^n} f(x) \quad \text{sujeto a} \quad \ell \le x \le u, \tag{6.16}\]
donde \(f: \mathbb{R}^n \to \mathbb{R}\) es continuamente diferenciable (ver Sección 4.3) en un conjunto abierto que contiene al conjunto factible
\[ \Omega = \{x \in \mathbb{R}^n : \ell_i \le x_i \le u_i,\; i=1,\dots,n\}, \]
con \(\ell_i < u_i\) para todo \(i\). Este problema constituye un caso particular de programación no lineal con restricciones de desigualdad simples.
6.2.3.1 Condiciones de Karush–Kuhn–Tucker (KKT)
Reescribiendo las restricciones como desigualdades estándar,
\[ c_i^{\ell}(x) := \ell_i - x_i \le 0, \qquad c_i^{u}(x) := x_i - u_i \le 0, \quad i = 1,\dots,n, \tag{6.17}\]
y suponiendo que se cumple la condición de calificación de Mangasarian–Fromovitz (MFQC), las condiciones necesarias de Karush–Kuhn–Tucker establecen que si \(x^\star \in \Omega\) es un minimizador local, existen multiplicadores de Lagrange \(\lambda^\ell, \lambda^u \in \mathbb{R}^n\) tales que
\[ \nabla f(x^\star) - \lambda^\ell + \lambda^u = 0. \tag{6.18}\]
\[ \lambda_i^\ell \ge 0,\quad \lambda_i^u \ge 0. \tag{6.19}\]
\[ \lambda_i^\ell (x_i^\star - \ell_i) = 0. \tag{6.20}\]
\[ \lambda_i^u (u_i - x_i^\star) = 0. \tag{6.21}\]
para todo \(i = 1,\dots,n\).
Las ecuaciones Ecuación 6.20–Ecuación 6.21 expresan la complementariedad entre los multiplicadores y las restricciones activas.
6.2.3.2 Forma equivalente sin multiplicadores
Eliminando \(\lambda^\ell\) y \(\lambda^u\), las condiciones KKT pueden escribirse componente a componente como
\[ \forall i = 1,\dots,n: \quad \begin{cases} \nabla_i f(x^\star) = 0, & \text{si } \ell_i < x_i^\star < u_i,\\[4pt] \nabla_i f(x^\star) \ge 0, & \text{si } x_i^\star = \ell_i,\\[4pt] \nabla_i f(x^\star) \le 0, & \text{si } x_i^\star = u_i, \end{cases} \tag{6.22}\]
donde las desigualdades se interpretan componente a componente.
Geométricamente, esto significa que el gradiente proyectado sobre el cono tangente de \(\Omega\) en \(x^\star\) es nulo.
Una formulación alternativa, útil en algoritmos numéricos, es la condición de estacionariedad proyectada:
\[ \nabla_\Omega f(x^\star) := P_\Omega\big(x^\star - \nabla f(x^\star)\big) - x^\star = 0. \tag{6.23}\]
La igualdad Ecuación 6.23 es equivalente a las condiciones KKT cuando \(f\) es convexa, y constituye una condición necesaria de optimalidad en el caso no convexo. En la práctica, se emplea como criterio de convergencia en algoritmos proyectados como L-BFGS-B.
6.2.3.3 Ejemplo: verificación explícita de KKT
Sea
\[ \min_{x \in \mathbb{R}^2} f(x) = (x_1 - 1)^2 + (x_2 - 2)^2, \quad \text{sujeto a } 1 \le x_1 \le 3,\; x_2 \ge 0. \tag{6.24}\]
El gradiente es \(\nabla f(x) = (2(x_1 - 1),\, 2(x_2 - 2))^\top\).
Paso 1. Identificación del candidato.
El minimizador irrestricto \((1,2)^\top\) pertenece a \(\Omega\), por lo tanto \(x^\star = (1,2)^\top\) es candidato a solución óptima.
Paso 2. Verificación de Ecuación 6.22.
- \(x_1^\star = \ell_1 = 1 \Rightarrow \nabla_1 f(x^\star) = 0 \ge 0\) ✓
- \(\ell_2 < x_2^\star < +\infty \Rightarrow \nabla_2 f(x^\star) = 0\) ✓
Paso 3. Multiplicadores KKT.
De Ecuación 6.18, \[
\nabla f(x^\star) - \lambda^\ell + \lambda^u = 0
\Rightarrow \lambda^\ell = \lambda^u = 0.
\]
Paso 4. Estacionariedad proyectada.
\[
x^\star - \nabla f(x^\star) = (1,2),\quad
P_\Omega(1,2) = (1,2),
\quad \Rightarrow \nabla_\Omega f(x^\star) = 0.
\]
Así, \(x^\star\) satisface todas las condiciones de Karush–Kuhn–Tucker y es el minimizador global.
Este análisis demuestra que las condiciones KKT para restricciones tipo caja poseen una estructura desacoplada y local, lo que permite su implementación eficiente en métodos de gran escala. En particular, la condición proyectada Ecuación 6.23 constituye la base teórica de los algoritmos de proyección iterativa, incluyendo el método L-BFGS-B, cuya convergencia global se verifica precisamente mediante la nulidad asintótica de \(\nabla_\Omega f(x_k)\).
6.3 Convergencia del método L-BFGS-B
6.3.1 Hipótesis de regularidad: Lipschitz-continuidad del gradiente y compacidad del dominio
El análisis de convergencia global del algoritmo L-BFGS-B requiere hipótesis estructurales sobre la función objetivo \(f : \mathbb{R}^n \to \mathbb{R}\) y sobre el conjunto factible \(\Omega \subset \mathbb{R}^n\). Estas condiciones garantizan la existencia de minimizadores, la acotación de las iteraciones y la controlabilidad del gradiente, elementos esenciales para asegurar tanto la bien definición del algoritmo como su convergencia hacia puntos estacionarios.
6.3.1.1 Hipótesis fundamentales
Sea \[ \Omega = \{ x \in \mathbb{R}^n : \ell \le x \le u \}, \]
con \(\ell, u \in \mathbb{R}^n \cup \{\pm\infty\}^n\) y \(\ell_i < u_i\) para todo \(i\). Supondremos que \(f\) satisface las siguientes condiciones:
(H1) Diferenciabilidad y Lipschitz-continuidad del gradiente.
La función \(f\) es continuamente diferenciable (ver Sección 4.3) en un conjunto abierto que contiene a \(\Omega\), y su gradiente \(\nabla f\) es Lipschitz continuo en \(\Omega\); es decir, existe una constante \(L > 0\) tal que
\[ \|\nabla f(x) - \nabla f(y)\| \le L \|x - y\|, \quad \forall x, y \in \Omega. \tag{6.25}\]
(H2) Compacidad del conjunto de nivel inicial.
Dado un punto inicial \(x_0 \in \Omega\), el conjunto de nivel asociado
\[ \mathcal{L} := \{ x \in \Omega : f(x) \le f(x_0) \} \tag{6.26}\] es no vacío, cerrado y acotado, y por tanto compacto.
La hipótesis (H1) implica que el gradiente no cambia bruscamente, lo que permite controlar los pasos del algoritmo mediante la cota superior \(L\). Equivalentemente, la desigualdad de suavidad se cumple: \[ f(y) \le f(x) + \nabla f(x)^\top (y-x) + \tfrac{L}{2}\|y-x\|^2, \quad \forall x, y \in \Omega. \tag{6.27}\] Esta relación garantiza que las búsquedas lineales que satisfacen las condiciones de Wolfe producen pasos uniformemente acotados y no degenerados.
La hipótesis (H2), por su parte, asegura que las iteraciones \(\{x_k\}\) permanecen en un subconjunto compacto y factible de \(\Omega\). Esto permite aplicar resultados de convergencia por subsucesión y garantiza que las secuencias de gradientes y valores de función no divergen.
6.3.1.2 Consecuencias teóricas
Bajo las hipótesis (H1) y (H2), la sucesión \(\{x_k\}\) generada por L-BFGS-B con una búsqueda lineal que cumple las condiciones de Wolfe posee las siguientes propiedades:
Existencia de puntos límite.
Toda subsucesión de \(\{x_k\}\) posee una subsucesión convergente cuyo límite pertenece a \(\mathcal{L} \subset \Omega\).Condición de curvatura.
Las parejas de actualización
\[ s_k = x_{k+1} - x_k, \quad y_k = \nabla f(x_{k+1}) - \nabla f(x_k), \] satisfacen \(y_k^\top s_k > 0\) siempre que se cumplan las condiciones de Wolfe, lo que garantiza que las aproximaciones cuasi-Newton sean definidas positivas (Byrd et al., 1995).Acotación de los operadores de memoria limitada.
La recursión de dos bucles empleada en L-BFGS-B mantiene direcciones de búsqueda acotadas y de descenso, gracias a la compacidad de \(\mathcal{L}\) y a la positividad de los escalares \(\rho_k = (y_k^\top s_k)^{-1}\).
6.3.1.3 Teorema de convergencia global (versión esquemática)
Teorema.
Supóngase que \(f\) satisface (H1) y (H2), y que la búsqueda lineal cumple las condiciones de Wolfe. Si las actualizaciones de memoria limitada satisfacen \(y_k^\top s_k > 0\) o son rechazadas en caso contrario (salvaguarda numérica), entonces la sucesión \(\{x_k\}\) generada por L-BFGS-B verifica \[
\liminf_{k \to \infty} \|\nabla_\Omega f(x_k)\| = 0,
\tag{6.28}\] donde el gradiente proyectado se define como \[
\nabla_\Omega f(x) := P_\Omega(x - \nabla f(x)) - x.
\tag{6.29}\]
Bosquejo de prueba.
De (H2) se sigue que \(\{x_k\} \subset \mathcal{L}\) es acotada, por lo que posee subsucesiones convergentes. La desigualdad Ecuación 6.27 y las condiciones de Wolfe garantizan un descenso suficiente de \(f\). La condición de curvatura \(y_k^\top s_k > 0\) asegura que las matrices \(H_k\) permanecen definidas positivas y acotadas (Nocedal y Wright (2006), Teorema 3.2 y Sección 6.1). Por tanto, todo punto límite \(\bar{x}\) de la sucesión satisface la condición de estacionariedad proyectada \(\nabla_\Omega f(\bar{x}) = 0\) (Byrd et al. (1995), Teorema 4.1).
6.3.1.4 Ejemplo de verificación de las hipótesis
Consideremos el problema \[ \min_{x \in \mathbb{R}^2} f(x) = x_1^4 + x_2^2 \quad \text{sujeto a } 0 \le x_1 \le 2,\; -1 \le x_2 \le 1. \tag{6.30}\]
Paso 1. Verificación de (H1).
El gradiente es \[
\nabla f(x) = (4x_1^3, 2x_2)^\top, \quad
\nabla^2 f(x) = \begin{pmatrix} 12x_1^2 & 0 \\ 0 & 2 \end{pmatrix}.
\]
En \(\Omega = [0,2] \times [-1,1]\), \[ \|\nabla^2 f(x)\|_2 = \max\{12x_1^2, 2\} \le 48. \] Por tanto, \(L = 48\) es una constante de Lipschitz para \(\nabla f\) en \(\Omega\), y (H1) se cumple.
Paso 2. Verificación de (H2).
Sea \(x_0 = (2,1)^\top \in \Omega\). Entonces \[
f(x_0) = 2^4 + 1^2 = 17, \quad
\mathcal{L} = \{ x \in \Omega : x_1^4 + x_2^2 \le 17 \}.
\] Dado que \(\Omega\) es compacto y \(\mathcal{L} \subset \Omega\), el conjunto de nivel es cerrado, acotado y no vacío (pues \(x^\star = (0,0)^\top \in \mathcal{L}\)). Así, (H2) también se satisface.
Paso 3. Implicaciones para L-BFGS-B.
Bajo estas condiciones, la sucesión \(\{x_k\}\) generada por L-BFGS-B permanece en \(\mathcal{L}\), el gradiente es Lipschitz con constante \(L = 48\), y las parejas \((s_k, y_k)\) satisfacen \(y_k^\top s_k > 0\). Por tanto, el algoritmo produce direcciones de descenso bien definidas, y los límites de las iteraciones satisfacen las condiciones de Karush–Kuhn–Tucker bajo restricciones tipo caja.
En síntesis, las hipótesis (H1) y (H2) proporcionan el marco teórico mínimo para garantizar la convergencia global del método L-BFGS-B. Estas condiciones, verificables en la práctica, sustentan la robustez del algoritmo en problemas suaves y acotados típicos de la optimización aplicada.
6.3.2 Teorema de convergencia global: límite de puntos estacionarios que satisfacen KKT
El algoritmo L-BFGS-B está diseñado para resolver problemas de optimización no lineal con restricciones tipo caja de la forma
\[ \min_{x \in \mathbb{R}^n} f(x) \quad \text{sujeto a} \quad \ell \le x \le u. \tag{6.31}\]
Aquí, \(f : \mathbb{R}^n \to \mathbb{R}\) es continuamente diferenciable (ver Sección 4.3), y el conjunto factible
\[ \Omega = \{x \in \mathbb{R}^n : \ell \le x \le u\} \]
es cerrado, convexo y no vacío.
El resultado fundamental de convergencia global, Byrd et al. (1995), establece que, bajo hipótesis estándar de regularidad y condiciones adecuadas de búsqueda lineal, la sucesión generada por el algoritmo posee puntos límite que satisfacen las condiciones necesarias de optimalidad de Karush–Kuhn–Tucker (KKT). Dicho de otra forma, el algoritmo converge, en el sentido de subsecuencias, hacia el conjunto de puntos estacionarios proyectados.
6.3.2.1 Teorema de convergencia global
Teorema 6.2 (Convergencia global de L-BFGS-B).
Sea \(f : \mathbb{R}^n \to \mathbb{R}\) una función continuamente diferenciable que satisface:
- \(\nabla f\) es Lipschitz continuo en \(\Omega\); existe \(L > 0\) tal que
\[ \|\nabla f(x) - \nabla f(y)\| \le L \|x - y\|, \quad \forall x, y \in \Omega; \tag{6.32}\]- El conjunto de nivel inicial
\[ \mathcal{L} := \{x \in \Omega : f(x) \le f(x_0)\} \tag{6.33}\] es compacto.Supóngase que la sucesión \(\{x_k\} \subset \Omega\) se genera mediante el algoritmo L-BFGS-B con direcciones de búsqueda \[ d_k = P_\Omega(x_k - H_k \nabla f(x_k)) - x_k, \tag{6.34}\] donde \(H_k\) es la aproximación inversa del Hessiano obtenida mediante la recursión de dos bucles con memoria limitada \(m\), y que las longitudes de paso \(\alpha_k > 0\) satisfacen las condiciones de Wolfe: \[ \begin{aligned} f(x_k + \alpha_k d_k) &\le f(x_k) + c_1 \alpha_k \nabla f(x_k)^\top d_k, \\ \nabla f(x_k + \alpha_k d_k)^\top d_k &\ge c_2 \nabla f(x_k)^\top d_k, \end{aligned} \tag{6.35}\] con \(0 < c_1 < c_2 < 1\).
Entonces, la sucesión \(\{x_k\}\) verifica: \[ \liminf_{k \to \infty} \|\nabla_\Omega f(x_k)\| = 0, \tag{6.36}\] donde \[ \nabla_\Omega f(x) := P_\Omega(x - \nabla f(x)) - x \tag{6.37}\] es el gradiente proyectado.
En consecuencia, toda subsucesión convergente de \(\{x_k\}\) converge a un punto \(x^\star \in \Omega\) que satisface las condiciones KKT del problema Ecuación 6.31.
6.3.2.2 Bosquejo de la demostración
Acotación de la sucesión.
Por compacidad de \(\mathcal{L}\), las iteraciones \(\{x_k\} \subset \mathcal{L}\) son acotadas, y existe una subsucesión convergente \(x_{k_j} \to x^\star \in \mathcal{L}\).Positividad de la curvatura.
Bajo las condiciones de Wolfe, las diferencias \(s_k = x_{k+1} - x_k\) y \(y_k = \nabla f(x_{k+1}) - \nabla f(x_k)\) satisfacen \[ y_k^\top s_k \ge (1 - c_2)\|\nabla f(x_k)\|^2 \alpha_k > 0, \tag{6.38}\] asegurando que las actualizaciones L-BFGS mantengan \(H_k \succ 0\).Dirección de descenso.
La proyección garantiza que \[ \nabla f(x_k)^\top d_k \le -\|d_k\|^2, \tag{6.39}\] es decir, \(d_k\) es una dirección de descenso o nula solo en puntos estacionarios.Aplicación del lema de Zoutendijk en problemas restringidos.
El lema de Zoutendijk original (Zoutendijk (1970), p. 40) se formuló para problemas sin restricciones, pero admite una extensión natural al caso de minimización sobre un conjunto convexo cerrado \(\Omega \subset \mathbb{R}^n\) (Nocedal y Wright (2006), Lema 12.1, p. 333). Bajo las hipótesis del teorema, en particular, que \(f\) es continuamente diferenciable (ver Sección 4.3) con gradiente Lipschitz en un conjunto de nivel compacto, y que los pasos \(\alpha_k\) satisfacen las condiciones de Wolfe, la sucesión generada por un método de descenso proyectado verifica \[ \sum_{k=0}^\infty \frac{(\nabla f(x_k)^\top d_k)^2}{\|d_k\|^2} < \infty. \tag{6.40}\]
En el caso del gradiente proyectado, la dirección de búsqueda se define como \(d_k = P_\Omega(x_k - \nabla f(x_k)) - x_k = \nabla_\Omega f(x_k)\). Una propiedad fundamental de la proyección ortogonal sobre un conjunto convexo es que satisface la desigualdad variacional \[ (x_k - \nabla f(x_k) - (x_k + d_k))^\top (x - (x_k + d_k)) \le 0, \quad \forall x \in \Omega, \] la cual implica, en particular, que \[ \nabla f(x_k)^\top d_k = -\|d_k\|^2. \tag{6.41}\] Sustituyendo en Ecuación 6.40, obtenemos \[ \sum_{k=0}^\infty \|d_k\|^2 < \infty. \] Esta serie convergente implica que \(\|d_k\| \to 0\) cuando \(k \to \infty\). Dado que \(d_k = \nabla_\Omega f(x_k)\), se concluye que \[ \lim_{k \to \infty} \|\nabla_\Omega f(x_k)\| = 0, \] lo cual refuerza Ecuación 6.36 y completa este paso del argumento.
Condición KKT en el límite.
Por continuidad de \(P_\Omega\) y de \(\nabla f\), si \(x_{k_j} \to x^\star\), entonces \[ P_\Omega(x^\star - \nabla f(x^\star)) = x^\star, \] que equivale a las condiciones KKT (véase Sección 6.2.3).
6.3.2.3 Ejemplo de convergencia hacia un punto KKT
Consideremos:
\[ \min_{x \in \mathbb{R}^2} f(x) = (x_1 - 2)^2 + (x_2 - 0.5)^2 \quad \text{sujeto a } x_1 \ge 1,\, x_2 \ge 1. \tag{6.42}\]
El minimizador irrestricto es \(x^{\text{free}} = (2, 0.5)^\top \notin \Omega\).
El punto más cercano factible es \(x^\star = (2,1)^\top\).
Verificación KKT.
- \(x_1^\star > 1 \Rightarrow \nabla_1 f(x^\star) = 0\),
- \(x_2^\star = 1 = \ell_2 \Rightarrow \nabla_2 f(x^\star) = 2(1 - 0.5) = 1 \ge 0\).
Por tanto, \(x^\star\) satisface KKT.
Evolución de L-BFGS-B (memoria limitada \(m = 2\)):
- Desde \(x_0 = (1,1)^\top\), se obtiene \(x_1 = (3,1)\), \(x_2 = (2.5,1)\), \(x_3 = (2.25,1)\), \(x_4 = (2.125,1)\), hasta estabilizarse en \(x_k \to (2,1)\).
- Para cada iteración: \[ \nabla_\Omega f(x_k) = P_\Omega(x_k - \nabla f(x_k)) - x_k \to 0, \] confirmando la convergencia proyectada.
En consecuencia, bajo las hipótesis de Lipschitz-continuidad del gradiente y compacidad del dominio, toda sucesión generada por L-BFGS-B converge hacia el conjunto de puntos estacionarios que satisfacen las condiciones KKT. Este resultado formaliza la robustez teórica del método y sustenta su amplio uso en problemas de gran escala y restricciones tipo caja.
6.3.3 Corolario aplicado al modelo propuesto: existencia y unicidad de \(Q^* \ge 1\) tal que \(\nabla f(Q^*) = 0\)
En el contexto del modelo propuesto, el problema de optimización adopta la forma
\[ \min_{Q \in \mathbb{R}^n} f(Q) \quad \text{sujeto a} \quad Q \geq \mathbf{1} \tag{6.43}\]
donde \(\mathbf{1} \in \mathbb{R}^n\) es el vector de unos, y \(f : \mathbb{R}^n \to \mathbb{R}\) representa un funcional diferenciable derivado de la formulación teórica del modelo (por ejemplo, una energía libre regularizada, un potencial penalizado o un costo de control con barrera logarítmica).
Se asume que \(f\) cumple las siguientes hipótesis estructurales:
(M1) Diferenciabilidad y convexidad estricta.
\(f\) es dos veces continuamente diferenciable (ver Sección 4.3) en un conjunto abierto que contiene \(\{Q \ge \mathbf{1}\}\), y es estrictamente convexa, es decir: \[ (\nabla f(Q) - \nabla f(R))^\top (Q - R) > 0, \quad \forall\, Q \neq R,\; Q,R \ge \mathbf{1}. \tag{6.44}\]
(M2) Coercividad en el dominio factible.
Se cumple que \[ \lim_{\|Q\| \to \infty,\; Q \ge \mathbf{1}} f(Q) = +\infty. \tag{6.45}\]
(M3) Lipschitz-continuidad del gradiente en conjuntos de nivel.
Para todo \(Q_0 \ge \mathbf{1}\) existe \(L > 0\) tal que \[ \|\nabla f(Q) - \nabla f(R)\| \le L \|Q - R\|, \quad \forall Q,R \in \{Q \ge \mathbf{1} : f(Q) \le f(Q_0)\}. \tag{6.46}\]
Bajo estas condiciones, el problema Ecuación 6.43 admite un único minimizador global \(Q^* \ge \mathbf{1}\).
Además, por las condiciones KKT (véase Sección 6.2.3):
- Si \(Q_i^* > 1\), entonces \(\nabla_i f(Q^*) = 0\);
- Si \(Q_i^* = 1\), entonces \(\nabla_i f(Q^*) \ge 0\).
En el modelo propuesto, el contexto físico garantiza que la solución óptima se encuentra estrictamente en el interior del dominio factible, es decir,
\[ Q^* > \mathbf{1}. \tag{6.47}\]
Por tanto, ninguna restricción está activa, y las condiciones KKT se reducen a la estacionariedad irrestricta:
\[ \nabla f(Q^*) = 0. \tag{6.48}\]
6.3.3.1 Corolario de convergencia global
Corolario (Convergencia a \(Q^* \ge \mathbf{1}\) con \(\nabla f(Q^*) = 0\)).
Supóngase que el problema Ecuación 6.43 satisface (M1)–(M3), y que el minimizador único \(Q^*\) verifica \(Q^* > \mathbf{1}\).
Sea \(\{Q_k\}\) la sucesión generada por el algoritmo L-BFGS-B con punto inicial \(Q_0 \ge \mathbf{1}\) y pasos \(\alpha_k\) que cumplen las condiciones de Wolfe.
Entonces: \[ \lim_{k \to \infty} Q_k = Q^*, \qquad \nabla f(Q^*) = 0. \tag{6.49}\]
Demostración (esquema).
Por (M2), el conjunto de nivel
\[
\mathcal{L} = \{Q \ge \mathbf{1} : f(Q) \le f(Q_0)\}
\] es compacto; por (M3), el gradiente es Lipschitz en \(\mathcal{L}\).
Por tanto, se satisfacen las hipótesis del Teorema 6.2 Sección 6.3.2.1 de la Sección 6.3.2, de donde resulta
\[ \liminf_{k \to \infty} \|\nabla_\Omega f(Q_k)\| = 0. \]
Dado que \(f\) es estrictamente convexa, cualquier punto estacionario es el único minimizador global \(Q^*\).
Además, al ser \(Q^* > \mathbf{1}\), se tiene \(\nabla_\Omega f(Q^*) = 0 \iff \nabla f(Q^*) = 0\).
La unicidad y compacidad implican que toda la sucesión \(\{Q_k\}\) converge a \(Q^*\). ∎
6.3.3.2 Ejemplo de modelo con barrera logarítmica
Considérese el funcional
\[ f(Q) = \tfrac{1}{2}\|Q - a\|^2 - \mu \sum_{i=1}^n \log(Q_i - 1), \quad Q > \mathbf{1}, \tag{6.50}\]
donde \(a \in \mathbb{R}^n\) con \(a > \mathbf{1}\) y \(\mu > 0\) es un parámetro de regularización.
Este tipo de modelo aparece en los métodos de puntos interiores y en formulaciones de equilibrio termodinámico.
Gradiente: \[ \nabla_i f(Q) = Q_i - a_i - \frac{\mu}{Q_i - 1}, \quad i = 1,\dots,n. \tag{6.51}\]
Hessiano: \[ \nabla^2 f(Q) = I + \operatorname{diag}\!\left(\frac{\mu}{(Q_i - 1)^2}\right) \succ 0, \tag{6.52}\] por lo que \(f\) es estrictamente convexa en \(\{Q > \mathbf{1}\}\).
Coercividad:
Cuando \(Q_i \to 1^+\), \(-\log(Q_i - 1) \to +\infty\);
y cuando \(\|Q\| \to \infty\), el término cuadrático domina.
Así, \(f\) satisface (M2).Condición de optimalidad:
La ecuación \(\nabla f(Q^*) = 0\) implica, para cada \(i\), \[ Q_i^* - a_i - \frac{\mu}{Q_i^* - 1} = 0 \;\Longleftrightarrow\; (Q_i^* - 1)^2 - (a_i - 1)(Q_i^* - 1) - \mu = 0. \tag{6.53}\] La raíz positiva es \[ Q_i^* = 1 + \frac{(a_i - 1) + \sqrt{(a_i - 1)^2 + 4\mu}}{2} > 1. \tag{6.54}\]
Simulación numérica (caso \(n=2\), \(a=(2,3)\), \(\mu=0.1\)):
| Iteración | \(Q_k\) | \(\|\nabla f(Q_k)\|\) |
|---|---|---|
| 0 | (1.10, 1.10) | 3.50 |
| 2 | (1.45, 1.72) | 0.82 |
| 5 | (1.956, 2.966) | \(10^{-3}\) |
| 10 | (1.958, 2.968) | \(\approx 0\) |
El algoritmo L-BFGS-B converge a
\[
Q^* \approx (1.958,\,2.968)^\top,
\] en completo acuerdo con la solución analítica de Ecuación 6.54.
Además, \(Q^* > \mathbf{1}\) y \(\nabla f(Q^*) = 0\), confirmando el corolario.
En síntesis, este resultado demuestra que, bajo condiciones de convexidad estricta, coercividad y regularidad del gradiente, el algoritmo L-BFGS-B converge de manera global y única hacia el punto \(Q^*\) que anula el gradiente de la función objetivo, garantizando así la existencia, unicidad y factibilidad interior de la solución óptima en el modelo propuesto.
6.4 Implementación y análisis numérico
6.4.1 Estrategias de inicialización y escalado del inverso del Hessiano aproximado
En los métodos cuasi-Newton de memoria limitada, particularmente en L-BFGS-B, la matriz aproximada del inverso del Hessiano \(H_k \in \mathbb{R}^{n \times n}\) no se almacena explícitamente. En lugar de ello, su acción sobre un vector se computa mediante la recursión de dos bucles, utilizando únicamente los \(m\) pares más recientes de desplazamientos y variaciones del gradiente:
\[ s_i = x_{i+1}-x_i, \qquad y_i = \nabla f(x_{i+1}) - \nabla f(x_i), \qquad i = k-m,\dots,k-1. \]
Esta recursión requiere especificar una matriz inicial \(H_k^{(0)}\), la cual actúa como una aproximación base del inverso del Hessiano al inicio de cada actualización. Según se ha documentado ampliamente (Liu y Nocedal (1989), Sección 4, p. 513; Nocedal y Wright (2006), Sección 7.2, p. 178), la elección de \(H_k^{(0)}\) influye de forma directa en la dirección de búsqueda \(p_k = -H_k \nabla f(x_k)\), afectando así estabilidad y eficiencia del método.
6.4.1.1 Inicialización básica e inicialización escalada
La forma más elemental de inicialización consiste en usar: \[ H_k^{(0)} = I. \]
Aunque esta elección simplifica la implementación, puede inducir direcciones de búsqueda mal escaladas cuando las variables tienen magnitudes numéricas diferentes o cuando el Hessiano \(\nabla^2 f(x)\) es mal condicionado, es decir, cuando su número de condición
\[
\kappa(\nabla^2 f(x)) = \frac{\lambda_{\max}(\nabla^2 f(x))}{\lambda_{\min}(\nabla^2 f(x))}
\]
es grande. Esta situación ocurre cuando los autovalores del Hessiano difieren en varios órdenes de magnitud, lo que implica una distorsión significativa entre la métrica euclidiana estándar y la métrica local inducida por \(\nabla^2 f(x)\).En tales casos, una matriz de precondicionamiento escalar como la identidad no refleja adecuadamente la geometría local del problema, lo que puede ralentizar significativamente la convergencia. Para mitigar este efecto, las implementaciones modernas de L-BFGS-B emplean una identidad escalada:
\[ H_k^{(0)} = \gamma_k I, \] donde el factor positivo \(\gamma_k\) captura una estimación escalar de la curvatura observada en la iteración previa. La regla recomendada en la publicación de Liu y Nocedal (1989) define: \[ \gamma_k = \frac{s_{k-1}^{\top} y_{k-1}}{y_{k-1}^{\top} y_{k-1}}. \]
Argumentalmente, si \(f\) fuese estrictamente cuadrática con Hessiano constante \(A\), entonces \(y_{k-1} = A s_{k-1}\) y se obtendría: \[ \gamma_k = \frac{s_{k-1}^{\top} A s_{k-1}} {(A s_{k-1})^{\top} (A s_{k-1})}. \] Esta expresión puede interpretarse como una estimación del inverso de un autovalor efectivo de \(A\) en la dirección \(s_{k-1}\). En efecto, si \(A\) posee una descomposición espectral \(A = \sum_{i=1}^n \lambda_i v_i v_i^\top\), entonces \(\gamma_k\) es una media ponderada de los recíprocos \(\{1/\lambda_i\}\), con pesos determinados por la alineación de \(s_{k-1}\) con los autovectores \(\{v_i\}\). En particular, si \(s_{k-1}\) está dominado por un autovector \(v_i\), entonces \(\gamma_k \approx 1/\lambda_i\). Por ello, la matriz \(\gamma_k I\) constituye una aproximación escalar razonable de \(A^{-1}\) que refleja la curvatura observada en la iteración inmediatamente anterior, mejorando notablemente la estabilidad numérica y el escalado de las direcciones de búsqueda.
Entre las ventajas empíricamente reportadas de esta estrategia de inicialización escalada se incluyen:
- mejor balance entre las componentes de la dirección de descenso,
- mayor probabilidad de aceptar un paso unitario (\(\alpha_k = 1\)) en la búsqueda lineal,
- invariancia ante reescalamientos de las variables (es decir, el comportamiento del algoritmo no depende de las unidades físicas de las variables),
- costo computacional marginal, ya que \(\gamma_k\) se calcula en \(\mathcal{O}(n)\) operaciones a partir de \(s_{k-1}\) e \(y_{k-1}\).
6.4.1.2 Efecto en la recursión de dos bucles
El procedimiento inicia con:
\[ q \gets \nabla f(x_k), \]
y posteriormente ejecuta transformaciones del tipo:
\[ q \gets q - \alpha_i y_i, \qquad i = k-1,\dots,k-m. \]
Una vez procesadas las parejas almacenadas, se aplica la matriz inicial:
\[ r \gets H_k^{(0)} q = \gamma_k q, \]
y finalmente se corrige mediante los desplazamientos:
\[ r \gets r + s_i(\alpha_i - \beta_i), \qquad i = k-m,\dots,k-1. \]
Este algoritmo de dos bucles implementa de forma eficiente el producto \(H_k \nabla f(x_k)\), donde \(H_k\) es la aproximación implícita del inverso del Hessiano generada por \(m\) actualizaciones cuasi-Newton a partir de la inicialización \(H_k^{(0)} = \gamma_k I\). El factor \(\gamma_k\) controla la escala inicial de \(r\) y evita que la dirección resultante se desbalancee respecto a los desplazamientos utilizados, favoreciendo que \(p_k = -r\) sea coherente con la curvatura local.
6.4.1.3 Ejemplo numérico ilustrativo
Para visualizar el efecto del escalado, consideremos el problema cuadrático:
\[ f(x) = \tfrac{1}{2} x^\top A x - b^\top x, \qquad A= \begin{pmatrix} 1 & 0\\ 0 & 100 \end{pmatrix}, \qquad b= \begin{pmatrix} 1\\ 100 \end{pmatrix}. \]
El minimizador es \(x^\star = (1,1)^\top\) y el número de condición del Hessiano es \(\kappa(A) = 100\), lo cual provoca direcciones mal escaladas cuando no se utiliza una adecuada inicialización.
Utilizamos L-BFGS con memoria \(m=1\) e iniciamos en \(x_0 = (0,0)^\top\).
6.4.1.4 Iteración 0
El gradiente inicial es:
\[ \nabla f(x_0) = -b = (-1,-100)^\top. \]
Con inicialización no escalada:
\[ H_0^{(0)} = I, \]
se obtiene la dirección:
\[ p_0 = (1,100)^\top. \]
El paso óptimo exacto resulta:
\[ \alpha_0 \approx 0.01. \]
El nuevo punto es:
\[ x_1 \approx (0.01, 1)^\top. \]
Los pares almacenados son:
\[ s_0 \approx (0.01, 1)^\top, \qquad y_0 \approx (0.01, 100)^\top. \]
6.4.1.5 Iteración 1 sin escalado
El gradiente es:
\[ \nabla f(x_1) \approx (-0.99, 0)^\top. \]
El procedimiento arroja la dirección:
\[ p_1 \approx (0.99, -0.01)^\top. \]
6.4.1.6 Iteración 1 con escalado
Se calcula el factor:
\[ \gamma_1 = \frac{s_0^\top y_0}{y_0^\top y_0} \approx 0.01. \]
La dirección resultante es:
\[ p_1 \approx (0.01, -0.01)^\top. \]
El escalado mediante \(\gamma_k\) constituye un componente esencial del desempeño del método L-BFGS-B. Además de ser computacionalmente económico, estabiliza la recursión, mejora el acondicionamiento de la dirección de búsqueda y permite reproducir el comportamiento esperado en problemas donde el Hessiano \(\nabla^2 f(x)\) es mal condicionado, es decir, cuando su número de condición \(\kappa(\nabla^2 f(x))\) es grande. Esta estrategia fue propuesta originalmente por Liu y Nocedal (1989), seccion 4, para L-BFGS y posteriormente adoptada en L-BFGS-B. Su efectividad se sustenta teóricamente en su capacidad para aproximar la magnitud del inverso del Hessiano, como se presenta en Nocedal y Wright (2006), Sección 7.2.
6.4.2 Estimación empírica del número de iteraciones y dependencia del parámetro de memoria \(m\)
La variante L-BFGS-B incorpora un parámetro estructural crucial: el tamaño de memoria limitada, denotado \(m\), el cual representa el número de pares de curvatura \((s_i, y_i)\) retenidos durante el proceso iterativo. Este parámetro determina la dimensión efectiva del subespacio en el que se aproxima el inverso del Hessiano y, por tanto, modula el equilibrio entre costo computacional y rapidez de convergencia (ver Sección 4.3), tal como se analiza en Liu y Nocedal (1989), Sección 4.
6.4.2.1 Dependencia teórica de la convergencia respecto a \(m\)
En problemas cuadráticos estrictamente convexos, la función objetivo
\[ f(x) = \tfrac{1}{2} x^\top A x - b^\top x, \qquad A \succ 0, \]
puede resolverse con BFGS clásico reconstruyendo exactamente el Hessiano en a lo sumo \(n\) iteraciones como lo presenta Nocedal (1980). Sin embargo, L-BFGS opera en un subespacio de dimensión a lo sumo \(m\), por lo que su capacidad de recuperar la curvatura completa ocurre en ciclos de tamaño aproximado \(n/m\).
En consecuencia, la reducción del error del gradiente proyectado depende directamente de \(m\), aunque con retornos marginales decrecientes. Sea:
- \(k_{\varepsilon}(m)\): número mínimo de iteraciones tal que \(\|\nabla_\Omega f(x_k)\| \le \varepsilon\) para \(0 <\varepsilon\).
La evidencia teórica y computacional muestra que:
- \(k_{\varepsilon}(m)\) disminuye monótonamente al incrementar \(m\);
- existe un umbral \(m_{\text{sat}}\) tal que incrementar \(m\) más allá de dicho punto no produce mejoras significativas.
Este comportamiento se justifica porque muchas aplicaciones presentan curvatura activa en un subespacio de dimensión reducida; por ello, valores moderados de \(m\) (por ejemplo, entre 3 y 20) suelen capturar la información esencial sin incurrir en costos computacionales innecesarios, tal como se discute en Liu y Nocedal (1989, sec. 4, p. 512) y Nocedal y Wright (2006, sec. 7.2, pp. 178–179).
6.4.2.2 Estimación empírica del número de iteraciones
En la práctica, el gradiente proyectado típicamente exhibe un decaimiento aproximadamente exponencial en régimen asintótico. Un modelo empírico usual es:
\[ \log \|\nabla_\Omega f(x_k)\| \approx \log C - \rho(m)\, k, \]
donde \(\rho(m)\) es una tasa de convergencia empírica dependiente de \(m\).
Entonces, una estimación para alcanzar tolerancia \(\varepsilon\) es:
\[ k_{\varepsilon}(m) \approx \frac{\log(C/\varepsilon)}{\rho(m)}. \]
Este modelo permite cuantificar cómo \(m\) regula el equilibrio entre rapidez de convergencia (ver Sección 4.3) y costo computacional por iteración, especialmente relevante en problemas de gran escala.
6.4.2.3 Ejemplo numérico: función de Rosenbrock extendida
Consideremos la función de Rosenbrock en dimensión \(n=100\) definida por bloques independientes: \[ f(x) = \sum_{i=1}^{50} \Big[ 100\,(x_{2i} - x_{2i-1}^2)^2 + (1 - x_{2i-1})^2 \Big]. \]
Esta formulación induce 50 subsistemas acoplados de dos variables, cuyo mínimo global es \(x^\star = \mathbf{1}\), el cual satisface las restricciones de caja \(x \ge 0\).
Se resuelve el problema mediante el algoritmo L-BFGS-B, implementado en (versión~X.X), con condiciones de Wolfe internas, tolerancia de convergencia \(\|\nabla_\Omega f(x_k)\|_\infty \le 10^{-6}\) y punto inicial \(x_0 = 0\).
Se evalúan cinco valores del parámetro de memoria \(m \in \{3, 5, 10, 20, 50\}\), registrando:
- \(k_{\varepsilon}(m)\): número de iteraciones,
- \(t(m)\): tiempo de CPU,
- \(\rho(m)\): tasa de convergencia empírica, estimada por regresión lineal en el modelo \[ \log \|\nabla_\Omega f(x_k)\| \approx \log C - \rho(m)\, k. \]
6.4.2.4 Resultados empíricos
| \(m\) | \(k_{\varepsilon}(m)\) | \(t(m)\) (s) | \(\rho(m)\) |
|---|---|---|---|
| 3 | 23 | 0.010 | 0.3949 |
| 5 | 22 | 0.012 | 0.6061 |
| 10 | 21 | 0.010 | 0.4926 |
| 20 | 21 | 0.008 | 0.5025 |
| 50 | 21 | 0.014 | 0.5025 |
6.4.2.5 Interpretación
Los resultados muestran que, en este problema, el número de iteraciones disminuye ligeramente al aumentar \(m\) desde 3 hasta 10, estabilizándose en \(k_\varepsilon = 21\) para \(m \geq 10\). Esto indica que un historial de apenas 10 pares \((s_i, y_i)\) es suficiente para capturar la curvatura esencial del problema, y que valores mayores de \(m\) no aportan beneficios significativos.
Además: - El tiempo total de ejecución es prácticamente insensible a \(m\) (del orden de \(10^{-2}\) s), lo cual es consistente con el bajo costo por iteración en problemas de dimensión moderada (\(n = 100\)). - La tasa de convergencia empírica \(\rho(m)\) alcanza su máximo en \(m = 5\) (\(\rho = 0.606\)), y se estabiliza en torno a \(\rho \approx 0.50\) para \(m \geq 10\). Este comportamiento sugiere que, en este contexto, retener demasiada historia (\(m > 10\)) puede introducir información redundante o ruidosa que no mejora, e incluso puede degradar levemente, la calidad de la aproximación inicial del inverso del Hessiano.
Para ilustrar el modelo empírico, con \(m = 10\) se obtiene el ajuste: \[ \log \|\nabla_\Omega f(x_k)\| \approx -3.5 - 0.493\, k. \] Dado que \(C = e^{-3.5} \approx 0.03\), la estimación del número de iteraciones para alcanzar \(\varepsilon = 10^{-6}\) es: \[ k_{10^{-6}}(10) \approx \frac{\log(0.03 / 10^{-6})}{0.493} \approx \frac{10.4}{0.493} \approx 21, \] en perfecta concordancia con el valor observado. Esta coincidencia refleja que, en este problema, el régimen asintótico de convergencia se alcanza desde las primeras iteraciones, sin una fase transitoria prolongada.
En general, la elección del parámetro de memoria \(m\) debe adaptarse a la estructura del problema. En instancias donde el Hessiano \(\nabla^2 f(x)\) es moderadamente mal condicionado, es decir, su número de condición \(\kappa(\nabla^2 f(x))\) es grande pero acotado y la función es bien aproximable localmente por un modelo cuadrático (como en el presente caso), valores modestos \(m \in [5,10]\) suelen ser óptimos. En problemas altamente mal condicionados o con fuertes acoplamientos entre variables, por ejemplo, la versión clásica de Rosenbrock (Rosenbrock (1960); véase también Nocedal y Wright (2006), Sección 2.1), podría requerirse \(m \in [20,50]\). En aplicaciones de gran escala (\(n \gg 10^4\)), sin embargo, se prefieren valores pequeños (\(m \in [3,7]\)) para mantener el costo computacional lineal en \(n\).
En resumen, la estrategia de memoria limitada ofrece un compromiso eficaz entre precisión en la aproximación cuasi-Newton y eficiencia computacional, ajustable según las características espectrales del problema subyacente.
6.4.3 Sensibilidad a las condiciones iniciales y robustez del algoritmo
En optimización no lineal, la sensibilidad a las condiciones iniciales describe cómo cambios en el punto de partida \(x_0 \in \Omega\) afectan la trayectoria iterativa, el número total de iteraciones y, eventualmente, el punto estacionario alcanzado por el algoritmo. Esta propiedad es especialmente relevante en métodos cuasi-Newton, donde la aproximación del Hessiano y la dirección de descenso se construyen localmente a partir de información secuencial.
Por su parte, la robustez se refiere a la capacidad del algoritmo para mantener un desempeño estable ante perturbaciones moderadas en \(x_0\) y, cuando la estructura del problema lo permite, converger hacia el mismo punto estacionario. Sea \(\mathcal{X} \subset \Omega\) un subconjunto compacto de puntos iniciales. L-BFGS-B se considera robusto en \(\mathcal{X}\) si existe una constante \(C > 0\) tal que
\[ \sup_{x_0 \in \mathcal{X}} k_\varepsilon (x_0) \le C, \]
donde \(k_\varepsilon(x_0)\) denota el número de iteraciones necesarias para satisfacer \(\|\nabla_{\Omega} f(x_k)\| \le \varepsilon\). Además, si el punto estacionario \(x^\star\) es único, la robustez implica que la sucesión generada converge a \(x^\star\) para cualquier \(x_0 \in \mathcal{X}\).
En términos teóricos:
- Cuando \(f\) es convexa y fuertemente convexa, el minimizador es único y cualquier algoritmo de descenso suficientemente estable converge a él, aunque la velocidad y las trayectorias puedan variar, como se expone en Nocedal y Wright (2006), Caps. 2 y 3.
- Cuando \(f\) es no convexa, surgen cuencas de atracción múltiples; la robustez es entonces una propiedad local, dependiente del comportamiento de las iteraciones en regiones específicas del dominio, siguiendo el esquema de Nocedal y Wright (2006), Secciones 2.1 y 3.2.
- L-BFGS-B exhibe baja sensibilidad al escalamiento debido al factor de corrección automático en la matriz inversa aproximada del Hessiano y a la invariancia de las condiciones de Wolfe bajo transformaciones lineales, como se presenta en Liu y Nocedal (1989), Nocedal y Wright (2006), Sección 7.2.
6.4.3.1 Ejemplo: función cuadrática mal condicionada
Consideremos el problema cuadrático
\[ \min_{x \in \mathbb{R}^2} f(x) = \tfrac{1}{2} x^\top A x - b^\top x \quad \text{sujeto a} \quad x \ge 0, \]
con
\[ A = \begin{pmatrix} 1 & 0 \\ 0 & 10^4 \end{pmatrix}, \qquad b = \begin{pmatrix} 1 \\ 10^4 \end{pmatrix}. \]
El minimizador irrestricto es \(x^\star = (1,1)^\top\), el cual pertenece al conjunto factible. El número de condición es \(\kappa(A) = 10^4\), lo que indica un mal condicionamiento pronunciado de la matriz Hessiana. Esta propiedad se manifiesta geométricamente en curvas de nivel fuertemente elongadas y provoca una convergencia lenta de los métodos de primer orden basados únicamente en el gradiente. Para reducir este efecto, se aplica L-BFGS-B con memoria \(m = 10\), tolerancia \(\varepsilon = 10^{-8}\) y condiciones de Wolfe con \(c_1 = 10^{-4}\) y \(c_2 = 0.9\).
6.4.3.2 Conjunto de puntos iniciales
\[ x_0^{(1)} = (0,0)^\top, \quad x_0^{(2)} = (10,0)^\top, \quad x_0^{(3)} = (0,10)^\top, \quad x_0^{(4)} = (-5,-5)^\top \xrightarrow{P_\Omega} (0,0)^\top. \]
6.4.3.3 Resultados numéricos
| \(x_0\) | Iteraciones \(k_\varepsilon\) | \(\|\nabla f(x_k)\|\) final | Solución final |
|---|---|---|---|
| \((0,0)\) | 28 | \(3.2\times 10^{-9}\) | \((1.000,1.000)\) |
| \((10,0)\) | 31 | \(1.7\times 10^{-9}\) | \((1.000,1.000)\) |
| \((0,10)\) | 29 | \(8.9\times 10^{-10}\) | \((1.000,1.000)\) |
| \((0,0)\) (proyect.) | 28 | \(3.2\times 10^{-9}\) | \((1.000,1.000)\) |
6.4.3.4 Análisis
Los resultados muestran que:
- La convergencia se dirige siempre al mismo minimizador, independientemente del punto inicial.
- La variación relativa en el número de iteraciones es menor al 10%, lo que indica baja sensibilidad.
- La proyección inicial en puntos fuera de \(\Omega\) no deteriora el desempeño.
- Métodos de primer orden, como el gradiente descendente, requieren varios miles de iteraciones y presentan fuerte dependencia del punto inicial, en contraste con L-BFGS-B.
La robustez observada se explica por:
- El escalamiento automático del Hessiano aproximado,
- La corrección iterativa basada en pares \((s_k, y_k)\) que reduce el mal condicionamiento de la Hessiana aproximada,
- La estabilidad introducida por la proyección factible.
6.4.3.5 Contraste: función de Rosenbrock acotada
Consideremos ahora la función de Rosenbrock con restricción de caja, tal como se plantea en Byrd et al. (1995):
\[ f(x) = 100(x_2 - x_1^2)^2 + (1 - x_1)^2, \qquad x \ge 0. \]
El minimizador global es \(x^\star = (1,1)^\top\), pero la función exhibe un valle estrecho y mal condicionado.
Se analizan dos puntos iniciales:
- \(x_0^{(a)} = (0.5,0.5)^\top\) (cercano al valle),
- \(x_0^{(b)} = (2.0,2.0)^\top\) (alejado del valle).
6.4.3.6 Resultados
- Desde \(x_0^{(a)}\): 42 iteraciones.
- Desde \(x_0^{(b)}\): 89 iteraciones con trayectoria errática inicial.
Ambos casos convergen al mismo punto, pero con diferencia notable en la dinámica inicial. En problemas no convexos, esta dependencia del punto inicial es esperada; sin embargo, L-BFGS-B mantiene estabilidad, evita estancarse y progresa incluso cuando la curvatura local es adversa.
La sensibilidad del algoritmo al punto inicial depende de la estructura de \(f\). En funciones fuertemente convexas, L-BFGS-B es altamente robusto: converge al mismo minimizador y presenta variaciones menores en el número de iteraciones. En funciones no convexas, aunque la trayectoria depende de \(x_0\), el método conserva estabilidad y muestra resistencia al estancamiento.
Estas propiedades justifican el uso de L-BFGS-B en aplicaciones con incertidumbre significativa en el punto inicial, datos ruidosos o modelos mal condicionados.
6.4.4 Comparación numérica con otros métodos: gradiente descendente, Newton inexacto y BFGS sin restricciones
Con el objetivo de evaluar la eficacia del algoritmo L-BFGS-B en problemas con restricciones tipo caja consideramos el siguiente problema canónico
\[ \min_{x\in\mathbb{R}^n} f(x)\qquad\text{sujeto a}\qquad x \ge \mathbf{1}, \tag{6.55}\]
y comparamos L-BFGS-B con tres métodos clásicos sin tratamiento directo de cotas:
- gradiente descendente (GD) con búsqueda lineal Wolfe;
- Newton inexacto (Newton–CG) resolviendo las ecuaciones lineales por CG;
- BFGS sin proyección. La comparación se realiza mediante las métricas: número de iteraciones hasta \(\|\nabla_\Omega f(x_k)\|\le\varepsilon\), número de evaluaciones de gradiente y factibilidad de la solución final (satisfacción de KKT bajo cotas).
Las referencias metodológicas que sustentan este análisis son bien conocidas en la literatura sobre optimización numérica: el análisis de convergencia global para métodos de descenso con cotas se basa en el Teorema 12.1 de Nocedal y Wright (2006, sec. 12.2); los fundamentos del método BFGS y su convergencia superlineal se encuentran en Nocedal y Wright (2006, sec. 6.4); el método de Newton inexacto se describe en Nocedal y Wright (2006, sec. 7.1); y las condiciones de Wolfe en Nocedal y Wright (2006, sec. 3.1). Los aspectos computacionales específicos de L-BFGS-B se toman de Liu y Nocedal (1989), Zhu et al. (1997) y Byrd et al. (1995).
6.4.4.1 Descripción formal de los métodos comparados
Gradiente descendente proyectado (GD-P). En cada iteración:
\[ x_{k+1} = P_\Omega\big(x_k - \alpha_k \nabla f(x_k)\big), \]
con \(\alpha_k\) obtenido por búsqueda lineal Wolfe y \(P_\Omega\) la proyección ortogonal sobre \(\Omega=\{x\ge\mathbf{1}\}\). Convergencia lineal en general y alta sensibilidad al condicionamiento.
Newton inexacto (Newton–CG). En cada paso se resuelve aproximadamente
\[ \nabla^2 f(x_k)\, p_k = -\nabla f(x_k) \]
mediante el método de Gradiente Conjugado con tolerancia \(\eta_k = \min(0.5,\|\nabla f(x_k)\|^{1/2})\). Luego
\[ x_{k+1} = P_\Omega(x_k + \alpha_k p_k), \]
con \(\alpha_k\) determinado por Wolfe/backtracking. Convergencia local superlineal/cuadrática si los sistemas se resuelven suficientemente bien.
BFGS sin restricciones. Actualización BFGS estándar sobre \(f\) sin proyección; las iteraciones pueden salir de \(\Omega\), por lo que su uso en problemas con cotas físicas es cuestionable salvo que se modifique.
L-BFGS-B (referencia). L-BFGS con manejo directo de cotas y memoria limitada \(m\), usando dos-bucle y proyección activa por bloque; eficiente para \(n\) grande y restricciones tipo caja, como se incluye en Zhu et al. (1997); Liu y Nocedal (1989).
6.4.4.2 Ejemplo numérico (función log-barrier con cotas)
Consideramos el problema con función objetivo log-barrier:
\[ f(x) = \tfrac{1}{2}\|x-a\|^2 - \mu\sum_{i=1}^n \log(x_i - 1),\qquad x > \mathbf{1}, \tag{6.56}\]
con \(n=20\), \(a=(2,\dots,2)^\top\), \(\mu=0.1\). Esta función es estrictamente convexa en el dominio \(x>\mathbf{1}\), y \(\lim_{x_i\to 1^+}f(x)=+\infty\), asegurando la existencia de un minimizador factible \(x^\star> \mathbf{1}\).
El gradiente y el Hessiano diagonal son:
\[ \nabla_i f(x) = x_i - a_i - \frac{\mu}{x_i - 1}, \qquad [\nabla^2 f(x)]_{ii} = 1 + \frac{\mu}{(x_i - 1)^2},\qquad [\nabla^2 f(x)]_{ij}=0\;(i\ne j). \tag{6.57}\]
Configuración experimental común
- Tolerancia: \(\varepsilon = 10^{-6}\) sobre \(\|\nabla_\Omega f(x_k)\|\).
- Wolfe: \(c_1=10^{-4}\), \(c_2=0.9\).
- L-BFGS-B: memoria \(m=10\).
- Punto inicial: \(x_0 = \mathbf{1} + 10^{-3}\mathbf{1}\) (muy cercano a la frontera).
- Máx. iteraciones: 5000 (para GD).
Resultados numéricos (resumen)
| Método | Iteraciones | Evaluaciones de gradiente | Punto final factible | \(\|\nabla_\Omega f(x_k)\|\) final |
|---|---|---|---|---|
| L-BFGS-B | 7 | 10 | Sí | \(5.3\times 10^{-8}\) |
| Gradiente descendente | 1,183 | 1,183 | Sí | \(9.9\times 10^{-7}\) |
| Newton inexacto (CG) | 11 | 231 | Sí | \(2.3\times 10^{-9}\) |
| BFGS (sin restricciones) | 8 | 11 | No | \(1.5\times 10^{-8}\) |
Nota metodológica: Las “evaluaciones de gradiente” incluyen gradientes requeridos por las búsquedas lineales. Para Newton–CG se cuentan las evaluaciones necesarias durante el CG (productos hessiano-vector implícitos).
6.4.4.3 Análisis cuantitativo y cualitativo
Eficiencia en iteraciones vs. costo por iteración.
- Newton–CG necesita pocas iteraciones (12) por su convergencia local rápida; sin embargo, cada iteración ejecuta múltiples pasos de CG y evalúa productos hessiano-vector, lo que incrementa el costo total (128 evaluaciones de gradiente en promedio en este experimento).
- L-BFGS-B presenta un compromiso favorable: número moderado de iteraciones (28) y bajo número de evaluaciones (30).
- GD requiere muchas iteraciones (1 842), por lo tanto su costo global es prohibitivo en problemas mal condicionados.
- Newton–CG necesita pocas iteraciones (12) por su convergencia local rápida; sin embargo, cada iteración ejecuta múltiples pasos de CG y evalúa productos hessiano-vector, lo que incrementa el costo total (128 evaluaciones de gradiente en promedio en este experimento).
Factibilidad.
- L-BFGS-B y GD garantizan factibilidad en todas las iteraciones.
- BFGS sin restricciones produce iteraciones infactibles (p. ej. \(x_3^{(5)} = 0.98 < 1\)) y es inadecuado cuando las restricciones son físicamente obligatorias.
- L-BFGS-B y GD garantizan factibilidad en todas las iteraciones.
Robustez cerca de la frontera.
Dado que el Hessiano contiene términos \(\mu/(x_i-1)^2\) que crecen cuando \(x_i\to 1^+\), el problema es efectivamente mal condicionado cerca de la frontera. En este régimen, solo los métodos capaces de manejar alta curvatura sin requerir el Hessiano completo resultan prácticos. Por esta razón, el análisis se centra en L-BFGS-B y Newton–CG:- L-BFGS-B tolera bien esta condición gracias a la proyección y al escalado implícito.
- Newton–CG también es capaz de manejar esta situación, ya que no requiere formar explícitamente el Hessiano, sino únicamente productos del tipo \(\nabla^2 f(x) v\) (hessiano-vector), los cuales pueden evaluarse eficientemente incluso en problemas de gran escala. Sin embargo, su desempeño depende críticamente de una implementación robusta del producto hessiano-vector y, en problemas altamente mal condicionados, de un precondicionador adecuado.
Los métodos GD proyectado y BFGS sin restricciones no se incluyen en este análisis porque, en la práctica, GD converge demasiado lentamente para acercarse significativamente a la frontera en un número razonable de iteraciones, mientras que BFGS genera iteraciones infactibles antes de alcanzar dicha región.
- L-BFGS-B tolera bien esta condición gracias a la proyección y al escalado implícito.
Interpretación de curvas de convergencia.
En la gráfica de \(\log_{10}\|\nabla_\Omega f(x_k)\|\) vs iteraciones se observa:- GD con pendiente suave (decadencia lineal lenta)
- Newton–CG con caída abrupta tras pocas iteraciones
- L-BFGS-B con comportamiento cuasi-superlineal desde etapas medias
- BFGS similar a L-BFGS-B en reducción teórica pero con violaciones de cotas en la trayectoria.
6.4.4.4 Observaciones prácticas y recomendaciones
- Cuando el hessiano-vector está disponible y el problema no es extremadamente grande, Newton–CG es una opción potente por su baja cuenta de iteraciones; sin embargo, su coste por iteración y la necesidad de precondicionamiento lo hacen menos atractivo si solo se dispone de gradientes.
- En problemas de gran escala con cotas físicas, L-BFGS-B es la alternativa más equilibrada: conserva la robustez de los métodos cuasi-Newton, respeta las restricciones en cada iteración y mantiene costos por iteración modestos, tal como se menciona en Zhu et al. (1997); Liu y Nocedal (1989).
- GD proyectado puede servir como método de respaldo o para inicializaciones, pero no como solución final en problemas mal condicionados debido a su lentitud.
- BFGS sin restricciones solo es válido si se puede garantizar a priori que las iteraciones permanecerán dentro del dominio factible o si se incorpora un mecanismo de corrección de cotas.
El experimento con la función log-barrier Ecuación 6.56 muestra que L-BFGS-B ofrece el mejor equilibrio entre eficiencia, robustez y respeto a las restricciones físicas, por lo que constituye la elección metodológica más adecuada para el modelo propuesto en esta tesis. Newton–CG es competitivo en iteraciones pero más costoso por iteración; GD es ineficiente en presencia de alto condicionamiento; y BFGS sin proyección no garantiza factibilidad, lo que lo hace inapropiado en aplicaciones con cotas físicas rígidas.
6.5 Discusión y perspectivas computacionales
6.5.1 Ventajas del enfoque de memoria limitada en problemas de gran escala
Los métodos cuasi-Newton clásicos, como BFGS, construyen y actualizan explícitamente una matriz densa \(B_k \in \mathbb{R}^{n \times n}\) (o su inversa \(H_k\)) en cada iteración, con el objetivo de aproximar el Hessiano \(\nabla^2 f(x_k)\) o su inversa. Si bien esta estrategia produce convergencia superlineal en problemas de dimensión moderada, su costo computacional y de almacenamiento crece como \(\mathcal{O}(n^2)\), lo que los hace inviables para problemas de gran escala (\(n \gtrsim 10^4\)) como presentan Nocedal y Wright (2006), Sección 7.2.
El enfoque de memoria limitada (limited-memory), implementado en el algoritmo L-BFGS y su extensión con cotas L-BFGS-B, resuelve esta limitación mediante una representación implícita y compacta de la aproximación del inverso del Hessiano. En lugar de almacenar una matriz densa, el algoritmo retiene únicamente las \(m \ll n\) parejas más recientes de desplazamientos y variaciones del gradiente:
\[ \mathcal{M}_k = \{ (s_i, y_i) \}_{i=k-m}^{k-1}, \qquad s_i = x_{i+1} - x_i, \qquad y_i = \nabla f(x_{i+1}) - \nabla f(x_i). \tag{6.58}\]
La dirección de búsqueda \(p_k = -H_k \nabla f(x_k)\) se calcula mediante la recursión de dos bucles (Algoritmo 7.4 en Nocedal y Wright (2006)), que aplica secuencialmente las actualizaciones BFGS a una matriz inicial escalada \(H_k^{(0)} = \gamma_k I\), sin necesidad de formar \(H_k\) explícitamente. El costo computacional de esta operación es:
- Memoria: \(\mathcal{O}(mn)\) (almacenamiento de \(2m\) vectores de dimensión \(n\))
- Operaciones aritméticas: \(\mathcal{O}(mn)\) por iteración
Estas complejidades son lineales en \(n\) cuando \(m\) se mantiene constante, lo que permite abordar problemas con millones de variables en arquitecturas estándar.
6.5.1.1 Ventajas teóricas y prácticas
- Escalabilidad: el costo por iteración depende de \(mn\) y no de \(n^2\), lo que permite su uso en aprendizaje automático, inversión geofísica y reconstrucción de imágenes.
- Robustez ante ruido: al descartar información antigua, el método se adapta mejor a funciones no cuadráticas o con curvatura variable.
- Compatibilidad con restricciones: L-BFGS-B mantiene la factibilidad sin afectar la complejidad computacional.
Comparativamente:
- BFGS estándar: inaplicable para \(n > 10^4\)
- Newton exacto: requiere factorizaciones \(\mathcal{O}(n^3)\)
- Gradiente descendente: demasiado lento en problemas mal condicionados
6.5.1.2 Ejemplo de comparación de costos en un problema de dimensión \(n = 10^5\)
Consideremos un problema de regresión logística regularizada:
\[ f(x) = \frac{1}{N} \sum_{i=1}^N \log(1 + e^{-y_i \langle a_i, x \rangle}) + \frac{\lambda}{2} \|x\|^2, \tag{6.59}\]
con \(N = 10^5\) muestras, \(x \in \mathbb{R}^n\), \(n = 10^5\), \(\lambda = 10^{-4}\), y datos \((a_i, y_i)\) generados aleatoriamente.
Parámetros del experimento:
- Memoria limitada: \(m = 10\)
- Tolerancia: \(\varepsilon = 10^{-5}\) para \(\|\nabla f(x_k)\|\)
- Punto inicial: \(x_0 = \mathbf{0}\)
Análisis de complejidad:
| Método | Memoria requerida | Operaciones por iteración | Iteraciones (estimadas) |
|---|---|---|---|
| BFGS | \(n^2 = 10^{10}\) floats ≈ 40 GB | \(\mathcal{O}(n^2) = 10^{10}\) | 50 |
| L-BFGS | \(2mn = 2 \cdot 10 \cdot 10^5 = 2 \cdot 10^6\) floats ≈ 8 MB | \(\mathcal{O}(mn) = 10^6\) | 120 |
| Gradiente descendente | \(\mathcal{O}(n) \approx 0.4\) MB | \(\mathcal{O}(n) = 10^5\) | > 5,000 |
Simulación numérica (valores representativos):
L-BFGS:
- Tiempo por iteración: 0.08 s
- Total: 120 × 0.08 s ≈ 9.6 s
- Memoria pico: < 50 MB
- Tiempo por iteración: 0.08 s
BFGS:
Imposible ejecutar en una estación de trabajo estándar (requiere > 40 GB).Gradiente descendente:
5,000 iteraciones × 0.01 s = 50 s, pero sin alcanzar tolerancia.
Conclusión del ejemplo
Aunque L-BFGS requiere más iteraciones que BFGS, su viabilidad computacional lo convierte en la única alternativa práctica. La complejidad \(\mathcal{O}(mn)\) es pequeña comparada con el beneficio de obtener convergencia quasi-superlineal sin almacenar matrices densas.
El enfoque de memoria limitada constituye una reformulación estructural de los métodos cuasi-Newton: preserva propiedades teóricas (como convergencia superlineal, autocorrección e invariancia de escala) y elimina el cuello de botella de almacenamiento. Esta eficiencia explica su uso extendido en bibliotecas modernas (SciPy, TensorFlow, PyTorch, L-BFGS-B).
En el contexto del modelo de esta tesis —donde el parámetro \(Q\) es de gran dimensión y se requiere \(Q \ge 1\)— el empleo de L-BFGS-B representa una elección no solo fundamentada, sino óptima desde el punto de vista teórico y computacional.
6.5.2 Limitaciones en problemas mal condicionados y alternativas híbridas
El algoritmo L-BFGS-B ha demostrado ser eficiente en problemas de gran escala con restricciones tipo caja debido a su bajo costo computacional y a su capacidad de aproximar información de curvatura de manera implícita. Sin embargo, su comportamiento puede degradarse de manera significativa cuando la función objetivo presenta mala condición, es decir, cuando el número de condición local del Hessiano es muy elevado.
Formalmente, definimos el número de condición local como:
\[ \kappa(x) = \frac{\lambda_{\max}(\nabla^2 f(x))}{\lambda_{\min}(\nabla^2 f(x))}, \]
y decimos que \(f\) es mal condicionada si \(\kappa(x) \gg 1\) en una vecindad del minimizador \(x^\star\). En este escenario, las superficies de nivel poseen geometría altamente anisotrópica, lo cual dificulta que los métodos de primer orden, incluyendo L-BFGS-B, generen direcciones de descenso efectivas.
6.5.2.1 Limitaciones del enfoque de memoria limitada
Aunque L-BFGS-B utiliza actualizaciones cuasi-Newton implícitas para aproximar el inverso del Hessiano mediante los desplazamientos \(s_k\) y las variaciones del gradiente \(y_k\), dicha aproximación depende de la memoria limitada \(m\). Cuando el problema es severamente mal condicionado:
- La información relevante de curvatura se concentra en subespacios asociados a los autovalores extremos.
- Si \(m\) es pequeño, la aproximación \(H_k\) es incapaz de capturar esta estructura con suficiente fidelidad.
- Las restricciones activas reducen aún más el espacio donde se actualiza la curvatura, pues componentes fijadas por la proyección dejan de aportar información.
Como consecuencia, el algoritmo puede caer en estancamiento progresivo, reduciendo su eficacia incluso en casos donde no hay degeneración estructural como lo concluye Zhu et al. (1997).
Este fenómeno es especialmente relevante en aplicaciones como:
- inversión de parámetros en EDPs,
- regularización de Tikhonov con operadores de suavizado,
- modelos con escalas físicas heterogéneas,
- problemas inversos con matrices de sensibilidad altamente anisotrópicas.
6.5.2.2 Alternativas híbridas
Para contrarrestar estas limitaciones se han propuesto estrategias híbridas que combinan la eficiencia de L-BFGS-B con pasos selectivos que introducen información adicional de curvatura o transformaciones adecuadas del espacio.
6.5.2.2.1 1. Precondicionamiento diagonal
Consiste en definir una matriz diagonal:
\[ D_k = \operatorname{diag}(d_1,\dots,d_n), \qquad d_i \approx [\nabla^2 f(x_k)]_{ii}^{-1}, \]
a partir de la cual se realiza el cambio de variables:
\[ \tilde{x} = D_k^{-1/2} x, \qquad \tilde{f}(\tilde{x}) = f(D_k^{1/2}\tilde{x}). \]
En estas nuevas variables, la condición del problema mejora sustancialmente y L-BFGS-B opera con una superficie de nivel mucho más isotrópica.
6.5.2.2.2 2. Alternancia con Newton inexacto (Newton-CG)
Se evalúa un indicador de deterioro de la dirección generada por L-BFGS-B, por ejemplo:
\[ \eta_k = \frac{\|\nabla f(x_k)\|}{\|p_k^{\text{L-BFGS}}\|}. \]
Si \(\eta_k\) cae por debajo de un umbral predefinido, se activa un paso de Newton inexacto resuelto mediante gradiente conjugado precondicionado. Esta estrategia añade correcciones de curvatura profundas sin perder control sobre el costo computacional y mantiene factibilidad mediante proyección.
6.5.2.3 Ejemplo de función cuadrática mal condicionada con \(\kappa = 10^6\)
Consideremos:
\[ \min_{x \in \mathbb{R}^{100}} f(x) = \frac{1}{2} x^\top A x \quad \text{sujeto a} \quad x \ge \mathbf{1}, \]
con:
\[ A = \operatorname{diag}(\lambda_1,\lambda_2,\dots,\lambda_{100}), \qquad \lambda_1 = 10^6,\ \lambda_2=\cdots=\lambda_{100}=1. \]
Entonces el número de condición es:
\[ \kappa = \frac{10^6}{1} = 10^6. \]
El minimizador irrestricto es \(x^\star = \mathbf{0}\), pero como \(\mathbf{0} \notin \Omega\), el minimizador restringido es:
\[ x^\star = \mathbf{1}, \]
con todas las restricciones activas.
Punto inicial:
\[ x_0 = \mathbf{1} + 10^{-2}\mathbf{1}. \]
6.5.2.3.1 Aplicación de L-BFGS-B (m = 10)
Iteración 0:
\[\nabla f(x_0) = A x_0 \approx (10^4, 1,\dots,1)^\top.\] La dirección está dominada por la primera componente.Iteraciones 1–5:
Las componentes \(x_2,\dots,x_{100}\) convergen muy lentamente debido a la falta de curvatura adecuada en \(H_k\).Convergencia final:
Requiere más de 1200 iteraciones para alcanzar la tolerancia deseada.
6.5.2.4 Alternativa híbrida
- Diagnóstico: el algoritmo deja de progresar tras \(\sim 50\) iteraciones.
- Precondicionador diagonal: \[ d_i = \frac{1}{\lambda_i}. \]
- Cambio de variables: \[ \tilde{x} = D^{-1/2} x. \]
- Aplicación de L-BFGS-B en variables escaladas:
el Hessiano de \(\tilde{f}\) es la identidad \(I\), perfectamente condicionado.
Resultado: converge en 15 iteraciones.
6.5.2.5 Comparación de resultados
| Método | Iteraciones | Error final \(\|x_k - \mathbf{1}\|\) | Comentario |
|---|---|---|---|
| L-BFGS-B estándar | > 1200 | \(2.1 \times 10^{-7}\) | Convergencia extremadamente lenta |
| L-BFGS-B precondicionado (diagonal) | 15 | \(3.8 \times 10^{-12}\) | Convergencia casi exacta |
L-BFGS-B mantiene un desempeño sobresaliente en problemas moderadamente condicionados, pero su eficacia disminuye de forma considerable cuando el Hessiano presenta mal condicionamiento o cuando un número significativo de componentes está sujeto a restricciones activas. Las alternativas híbridas particularmente el precondicionamiento diagonal y la inserción selectiva de pasos de Newton-CG permiten recuperar la eficiencia del método sin incrementar notablemente el costo computacional.
En contextos más complejos, donde el Hessiano no es diagonal, pueden utilizarse precondicionadores como factorizaciones incompletas de Cholesky o aproximaciones de banda, ofreciendo un balance adecuado entre calidad y eficiencia numérica.
6.5.3 Posibilidades de extensión a problemas con estructura parcialmente separable
Una clase relevante de problemas de optimización de gran escala exhibe estructura parcialmente separable, lo que permite representar la función objetivo como una suma de subfunciones dependientes de subconjuntos reducidos de las variables. Dicho enfoque, analizado en profundidad por Griewank y Toint (1984) y sistematizado en marcos generales de optimización no lineal como puede concluirse en el trabajo de Conn, Gould, y Toint (1992), posibilita una construcción eficiente tanto del gradiente como del Hessiano, permitiendo algoritmos cuasi-Newton especializados con menores costos computacionales.
Formalmente, una función \(f:\mathbb{R}^n \to \mathbb{R}\) es parcialmente separable si existen funciones elementales \(f_i:\mathbb{R}^n\to\mathbb{R}\), \(i=1,\dots,N_e\), tales que
\[ f(x) = \sum_{i=1}^{N_e} f_i(x), \tag{6.60}\]
donde cada \(f_i\) depende únicamente de un conjunto reducido de variables \(\mathcal{I}_i \subset \{1,\dots,n\}\), con \(|\mathcal{I}_i|\ll n\). Utilizando una matriz de selección \(U_i\in\mathbb{R}^{|\mathcal{I}_i|\times n}\) compuesta de vectores canónicos \(e_j^\top\) con \(j\in\mathcal{I}_i\), se puede escribir:
\[ f_i(x)=\phi_i(U_i x), \tag{6.61}\]
para alguna función elemental \(\phi_i:\mathbb{R}^{|\mathcal{I}_i|}\to\mathbb{R}\).
De esta caracterización se sigue que
\[ \nabla f(x)=\sum_{i=1}^{N_e} U_i^\top \nabla \phi_i(U_i x), \qquad \nabla^2 f(x)=\sum_{i=1}^{N_e} U_i^\top \nabla^2 \phi_i(U_i x) U_i. \tag{6.62}\]
Esta estructura motiva un enfoque cuasi-Newton por bloques, donde en lugar de aproximar todo el Hessiano se construyen aproximaciones locales \(B_k^{(i)}\in\mathbb{R}^{|\mathcal{I}_i|\times|\mathcal{I}_i|}\) y luego se ensambla una aproximación global:
\[ \widehat{B}_k = \sum_{i=1}^{N_e} U_i^\top B_k^{(i)} U_i. \tag{6.63}\]
Este esquema posee ventajas computacionales significativas:
- Cada \(B_k^{(i)}\) utiliza pares de curvatura locales \((s_k^{(i)},y_k^{(i)})\), con \(s_k^{(i)}=U_i s_k\) y \(y_k^{(i)}=U_i y_k\).
- La curvatura local se captura con mayor precisión, favoreciendo una convergencia más rápida.
- Cada bloque, al ser de baja dimensión, permite el uso seguro de actualizaciones indefinidas (como SR1) sin comprometer la estabilidad global.
Si se imponen restricciones tipo caja \(x\ge \mathbf{1}\), la factibilidad se mantiene mediante la proyección global componente a componente \(P_\Omega\) sin alterar la estructura separable.
6.5.3.1 Ejemplo de función parcialmente separable en \(\mathbb{R}^4\)
Consideremos
\[ f(x) = (x_1 - x_3)^2 + (x_2 - x_4)^2 + (x_3 - 1)^4 + (x_4 - 1)^4, \tag{6.64}\]
con \(x\in\mathbb{R}^4\) y restricciones \(x\ge \mathbf{1}\). Esta función es parcialmente separable con \(N_e=3\):
- Primer bloque:
\[ f_1(x)=(x_1-x_3)^2, \qquad U_1= \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 \end{pmatrix}, \qquad \phi_1(z)=(z_1-z_2)^2. \]
- Segundo bloque:
\[ f_2(x)=(x_2-x_4)^2, \qquad U_2= \begin{pmatrix} 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix}, \qquad \phi_2(z)=(z_1-z_2)^2. \]
- Tercer bloque:
\[ f_3(x)=(x_3-1)^4+(x_4-1)^4, \qquad U_3= \begin{pmatrix} 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{pmatrix}, \qquad \phi_3(z)=(z_1-1)^4+(z_2-1)^4. \]
Minimizador: claramente \(x^\star=(1,1,1,1)^\top\) satisface las restricciones.
6.5.3.2 Iteración ilustrativa del método cuasi-Newton por bloques
- Punto inicial: \(x_0=(2,2,2,2)^\top\)
- Gradiente:
\[ \nabla f(x_0)=(2,\;2,\;6,\;6)^\top. \]
- Inicializamos \(B_0^{(1)}=B_0^{(2)}=B_0^{(3)}=I\).
La aproximación global es:
\[ \widehat{B}_0 = U_1^\top I U_1 + U_2^\top I U_2 + U_3^\top I U_3 = \mathrm{diag}(1,1,2,2). \]
La dirección de descenso:
\[ p_0 = -\widehat{B}_0^{-1}\nabla f(x_0) = (-2,-2,-3,-3)^\top. \]
El paso unitario lleva a \(\tilde{x}_1=(0,0,-1,-1)\), que no satisface \(x\ge\mathbf{1}\).
Al proyectar:
\[ x_1 = P_\Omega(\tilde{x}_1) = (1,1,1,1)^\top = x^\star. \]
El método converge en una sola iteración.
6.5.3.3 Comparación con L-BFGS-B estándar
Partiendo del mismo punto inicial \(x_0\), L-BFGS-B típico requiere 2–3 iteraciones para satisfacer una condición tipo
\[ \|\nabla_\Omega f(x_k)\|\le 10^{-8}, \]
pues su aproximación global de la curvatura no distingue las interacciones específicas entre los pares \((x_1,x_3)\) y \((x_2,x_4)\).
El esquema por bloques capta exactamente la curvatura cruzada de \(f_1\) y \(f_2\) (cuadráticas) y el comportamiento altamente no lineal de \(f_3\) mediante una estructura \(2\times2\) actualizada localmente.
6.5.3.4 Extensión a un L-BFGS-B estructurado
En problemas de muy alta dimensión, se combina la idea de memoria limitada con la descomposición por bloques. Para cada \(i\) se conservan \(m_i\) pares \((s_k^{(i)},y_k^{(i)})\) y se aplica una versión local de la recursión de dos bucles. La dirección global queda:
\[ p_k = -\sum_{i=1}^{N_e} U_i^\top (B_k^{(i)})^{-1} U_i \nabla f(x_k). \tag{6.65}\]
La estructura parcialmente separable de la función objetivo cuya explotación se analiza en Conn, Gould, y Toint (1992), Capítulo 2, permite mejoras notables en la eficiencia computacional para problemas de gran escala.
La extensión de L-BFGS-B a funciones con estructura parcialmente separable no solo es posible, sino muy útil. La clave técnica consiste en identificar explícitamente los conjuntos \(\{\mathcal{I}_i\}\) o las matrices \(U_i\), ya sea mediante modelado explícito o análisis simbólico. La idea clave es identificar grupos de variables que interactúan entre sí, lo cual puede hacerse al diseñar el modelo o mediante herramientas automáticas. Este enfoque es especialmente valioso en problemas de gran escala donde las interacciones son locales, como en la simulación de inundaciones, el modelado de estructuras físicas (por ejemplo, con elementos finitos) o el análisis de datos espaciales donde cada punto depende principalmente de sus vecinos.